 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection Enhancement and Feature Space Visualization for Speech-Based Emotion Recognition
Aug 19, 2022
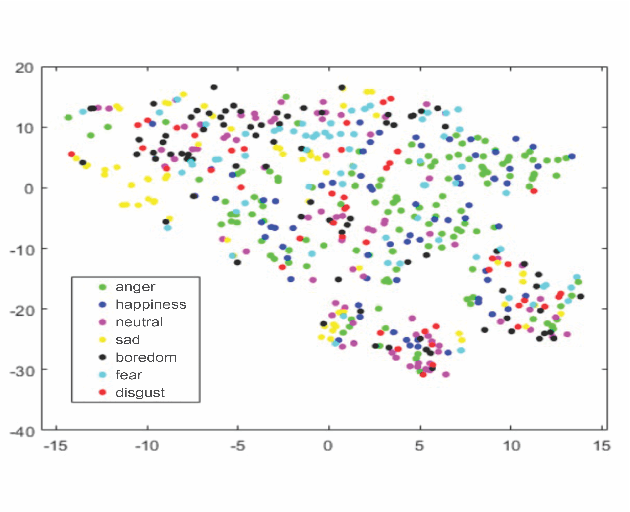
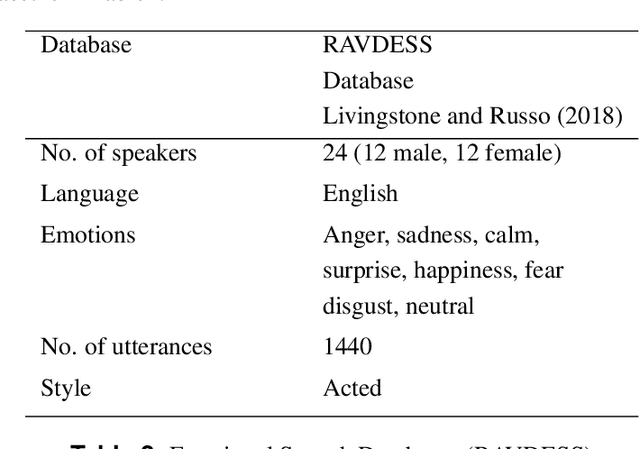
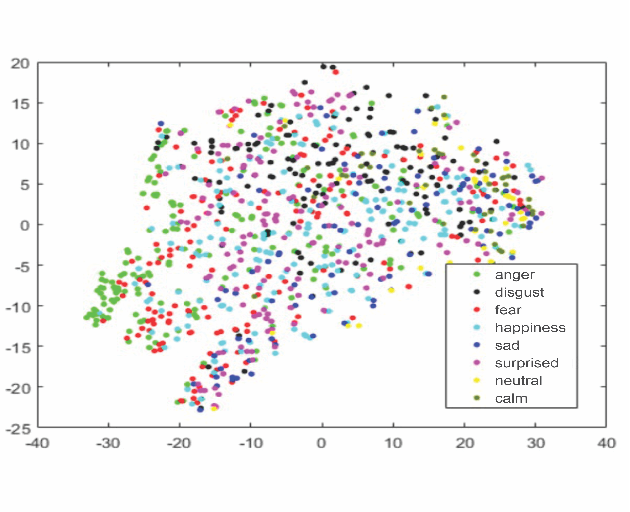
Robust speech emotion recognition relies on the quality of the speech features. We present speech features enhancement strategy that improves speech emotion recognition. We used the INTERSPEECH 2010 challenge feature-set. We identified subsets from the features set and applied Principle Component Analysis to the subsets. Finally, the features are fused horizontally. The resulting feature set is analyzed using t-distributed neighbour embeddings (t-SNE) before the application of features for emotion recognition. The method is compared with the state-of-the-art methods used in the literature. The empirical evidence is drawn using two well-known datasets: Emotional Speech Dataset (EMO-DB) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) for two languages, German and English, respectively. Our method achieved an average recognition gain of 11.5\% for six out of seven emotions for the EMO-DB dataset, and 13.8\% for seven out of eight emotions for the RAVDESS dataset as compared to the baseline study.