 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel method for Causal Structure Discovery from EHR data, a demonstration on type-2 diabetes mellitus
Nov 11, 2020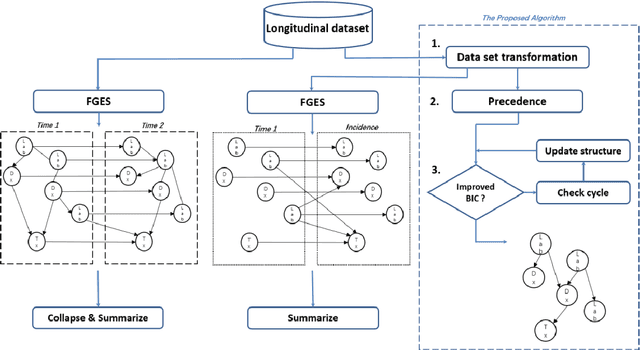
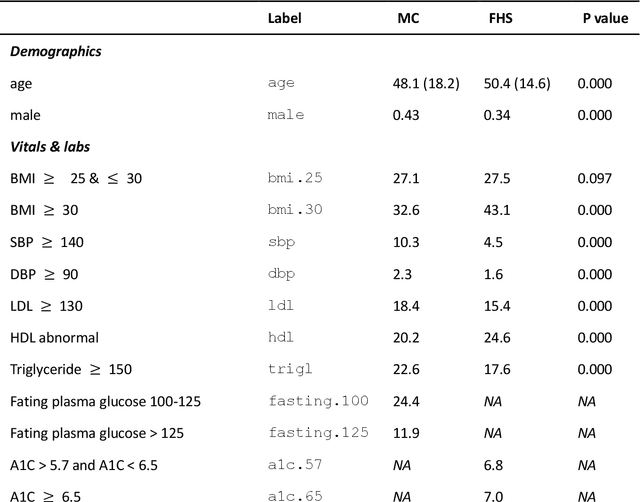
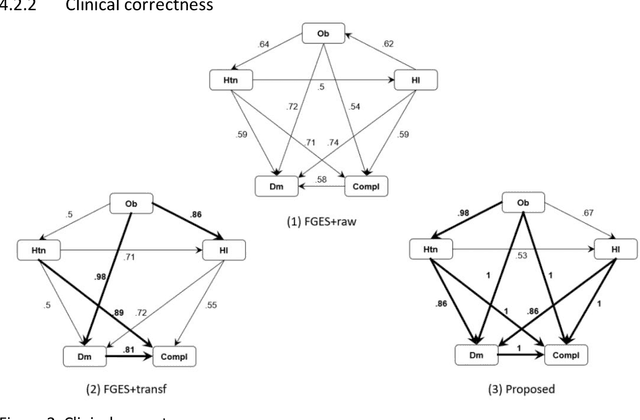

Introduction: The discovery of causal mechanisms underlying diseases enables better diagnosis, prognosis and treatment selection. Clinical trials have been the gold standard for determining causality, but they are resource intensive, sometimes infeasible or unethical. Electronic Health Records (EHR) contain a wealth of real-world data that holds promise for the discovery of disease mechanisms, yet the existing causal structure discovery (CSD) methods fall short on leveraging them due to the special characteristics of the EHR data. We propose a new data transformation method and a novel CSD algorithm to overcome the challenges posed by these characteristics. Materials and methods: We demonstrated the proposed methods on an application to type-2 diabetes mellitus. We used a large EHR data set from Mayo Clinic to internally evaluate the proposed transformation and CSD methods and used another large data set from an independent health system, Fairview Health Services, as external validation. We compared the performance of our proposed method to Fast Greedy Equivalence Search (FGES), a state-of-the-art CSD method in terms of correctness, stability and completeness. We tested the generalizability of the proposed algorithm through external validation. Results and conclusions: The proposed method improved over the existing methods by successfully incorporating study design considerations, was robust in face of unreliable EHR timestamps and inferred causal effect directions more correctly and reliably. The proposed data transformation successfully improved the clinical correctness of the discovered graph and the consistency of edge orientation across bootstrap samples. It resulted in superior accuracy, stability, and completeness.
Predictive and Causal Implications of using Shapley Value for Model Interpretation
Aug 12, 2020Shapley value is a concept from game theory. Recently, it has been used for explaining complex models produced by machine learning techniques. Although the mathematical definition of Shapley value is straight-forward, the implication of using it as a model interpretation tool is yet to be described. In the current paper, we analyzed Shapley value in the Bayesian network framework. We established the relationship between Shapley value and conditional independence, a key concept in both predictive and causal modeling. Our results indicate that, eliminating a variable with high Shapley value from a model do not necessarily impair predictive performance, whereas eliminating a variable with low Shapley value from a model could impair performance. Therefore, using Shapley value for feature selection do not result in the most parsimonious and predictively optimal model in the general case. More importantly, Shapley value of a variable do not reflect their causal relationship with the target of interest.