 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Style Transfer for Artistic Image Generation using VGG19
Jan 16, 2025
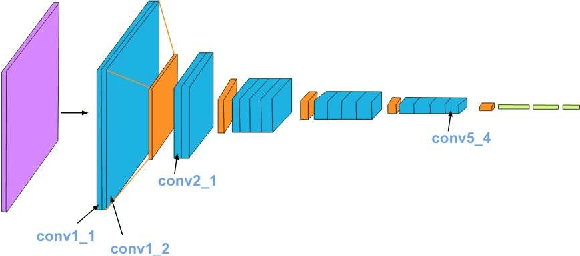
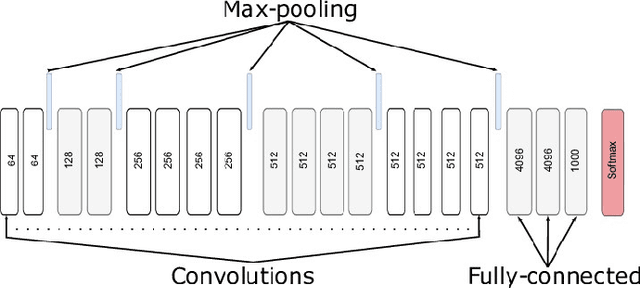

Throughout history, humans have created remarkable works of art, but artificial intelligence has only recently started to make strides in generating visually compelling art. Breakthroughs in the past few years have focused on using convolutional neural networks (CNNs) to separate and manipulate the content and style of images, applying texture synthesis techniques. Nevertheless, a number of current techniques continue to encounter obstacles, including lengthy processing times, restricted choices of style images, and the inability to modify the weight ratio of styles. We proposed a neural style transfer system that can add various artistic styles to a desired image to address these constraints allowing flexible adjustments to style weight ratios and reducing processing time. The system uses the VGG19 model for feature extraction, ensuring high-quality, flexible stylization without compromising content integrity.
Assessment of Transformer-Based Encoder-Decoder Model for Human-Like Summarization
Oct 22, 2024In recent times, extracting valuable information from large text is making significant progress. Especially in the current era of social media, people expect quick bites of information. Automatic text summarization seeks to tackle this by slimming large texts down into more manageable summaries. This important research area can aid in decision-making by digging out salient content from large text. With the progress in deep learning models, significant work in language models has emerged. The encoder-decoder framework in deep learning has become the central approach for automatic text summarization. This work leverages transformer-based BART model for human-like summarization which is an open-ended problem with many challenges. On training and fine-tuning the encoder-decoder model, it is tested with diverse sample articles and the quality of summaries of diverse samples is assessed based on human evaluation parameters. Further, the finetuned model performance is compared with the baseline pretrained model based on evaluation metrics like ROUGE score and BERTScore. Additionally, domain adaptation of the model is required for improved performance of abstractive summarization of dialogues between interlocutors. On investigating, the above popular evaluation metrics are found to be insensitive to factual errors. Further investigation of the summaries generated by finetuned model is done using the contemporary evaluation metrics of factual consistency like WeCheck and SummaC. Empirical results on BBC News articles highlight that the gold standard summaries written by humans are more factually consistent by 17% than the abstractive summaries generated by finetuned model.
VERITAS-NLI : Validation and Extraction of Reliable Information Through Automated Scraping and Natural Language Inference
Oct 12, 2024



In today's day and age where information is rapidly spread through online platforms, the rise of fake news poses an alarming threat to the integrity of public discourse, societal trust, and reputed news sources. Classical machine learning and Transformer-based models have been extensively studied for the task of fake news detection, however they are hampered by their reliance on training data and are unable to generalize on unseen headlines. To address these challenges, we propose our novel solution, leveraging web-scraping techniques and Natural Language Inference (NLI) models to retrieve external knowledge necessary for verifying the accuracy of a headline. Our system is evaluated on a diverse self-curated evaluation dataset spanning over multiple news channels and broad domains. Our best performing pipeline achieves an accuracy of 84.3% surpassing the best classical Machine Learning model by 33.3% and Bidirectional Encoder Representations from Transformers (BERT) by 31.0% . This highlights the efficacy of combining dynamic web-scraping with Natural Language Inference to find support for a claimed headline in the corresponding externally retrieved knowledge for the task of fake news detection.