 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing and Learning on Combinatorial Data
Feb 07, 2025The twenty-first century is a data-driven era where human activities and behavior, physical phenomena, scientific discoveries, technology advancements, and almost everything that happens in the world resulting in massive generation, collection, and utilization of data. Connectivity in data is a crucial property. A straightforward example is the World Wide Web, where every webpage is connected to other web pages through hyperlinks, providing a form of directed connectivity. Combinatorial data refers to combinations of data items based on certain connectivity rules. Other forms of combinatorial data include social networks, meshes, community clusters, set systems, and molecules. This Ph.D. dissertation focuses on learning and computing with combinatorial data. We study and examine topological and connectivity features within and across connected data to improve the performance of learning and achieve high algorithmic efficiency.
GEFL: Extended Filtration Learning for Graph Classification
Jun 04, 2024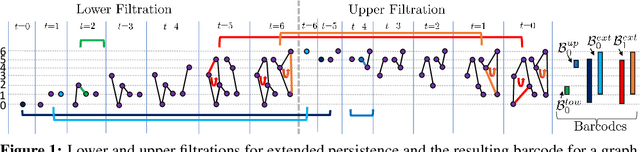
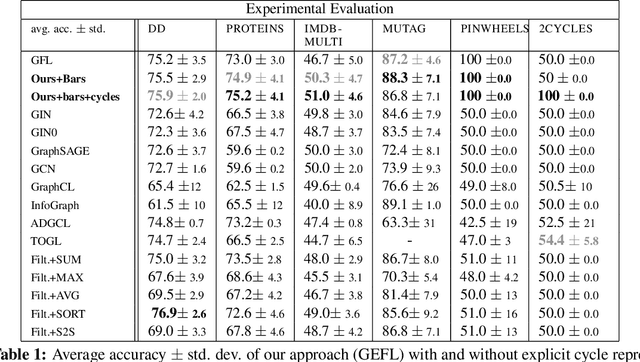
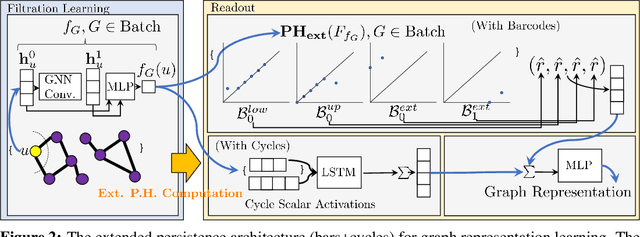
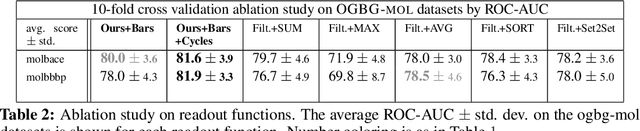
Extended persistence is a technique from topological data analysis to obtain global multiscale topological information from a graph. This includes information about connected components and cycles that are captured by the so-called persistence barcodes. We introduce extended persistence into a supervised learning framework for graph classification. Global topological information, in the form of a barcode with four different types of bars and their explicit cycle representatives, is combined into the model by the readout function which is computed by extended persistence. The entire model is end-to-end differentiable. We use a link-cut tree data structure and parallelism to lower the complexity of computing extended persistence, obtaining a speedup of more than 60x over the state-of-the-art for extended persistence computation. This makes extended persistence feasible for machine learning. We show that, under certain conditions, extended persistence surpasses both the WL[1] graph isomorphism test and 0-dimensional barcodes in terms of expressivity because it adds more global (topological) information. In particular, arbitrarily long cycles can be represented, which is difficult for finite receptive field message passing graph neural networks. Furthermore, we show the effectiveness of our method on real world datasets compared to many existing recent graph representation learning methods.
Expressive Higher-Order Link Prediction through Hypergraph Symmetry Breaking
Feb 17, 2024A hypergraph consists of a set of nodes along with a collection of subsets of the nodes called hyperedges. Higher-order link prediction is the task of predicting the existence of a missing hyperedge in a hypergraph. A hyperedge representation learned for higher order link prediction is fully expressive when it does not lose distinguishing power up to an isomorphism. Many existing hypergraph representation learners, are bounded in expressive power by the Generalized Weisfeiler Lehman-1 (GWL-1) algorithm, a generalization of the Weisfeiler Lehman-1 algorithm. However, GWL-1 has limited expressive power. In fact, induced subhypergraphs with identical GWL-1 valued nodes are indistinguishable. Furthermore, message passing on hypergraphs can already be computationally expensive, especially on GPU memory. To address these limitations, we devise a preprocessing algorithm that can identify certain regular subhypergraphs exhibiting symmetry. Our preprocessing algorithm runs once with complexity the size of the input hypergraph. During training, we randomly replace subhypergraphs identified by the algorithm with covering hyperedges to break symmetry. We show that our method improves the expressivity of GWL-1. Our extensive experiments also demonstrate the effectiveness of our approach for higher-order link prediction on both graph and hypergraph datasets with negligible change in computation.