 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity-Enhancing Digital Twins: Characteristics, Indicators, and Future Perspectives
May 10, 2023The term "digital twin" (DT) has become a key theme of the cyber-physical systems (CPSs) area, while remaining vaguely defined as a virtual replica of an entity. This article identifies DT characteristics essential for enhancing CPS security and discusses indicators to evaluate them.
Finding Minimum-Cost Explanations for Predictions made by Tree Ensembles
Mar 16, 2023The ability to explain why a machine learning model arrives at a particular prediction is crucial when used as decision support by human operators of critical systems. The provided explanations must be provably correct, and preferably without redundant information, called minimal explanations. In this paper, we aim at finding explanations for predictions made by tree ensembles that are not only minimal, but also minimum with respect to a cost function. To this end, we first present a highly efficient oracle that can determine the correctness of explanations, surpassing the runtime performance of current state-of-the-art alternatives by several orders of magnitude when computing minimal explanations. Secondly, we adapt an algorithm called MARCO from related works (calling it m-MARCO) for the purpose of computing a single minimum explanation per prediction, and demonstrate an overall speedup factor of two compared to the MARCO algorithm which enumerates all minimal explanations. Finally, we study the obtained explanations from a range of use cases, leading to further insights of their characteristics. In particular, we observe that in several cases, there are more than 100,000 minimal explanations to choose from for a single prediction. In these cases, we see that only a small portion of the minimal explanations are also minimum, and that the minimum explanations are significantly less verbose, hence motivating the aim of this work.
Scaling up Memory-Efficient Formal Verification Tools for Tree Ensembles
May 06, 2021
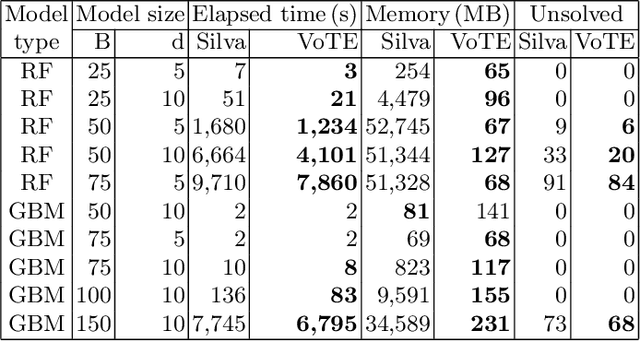
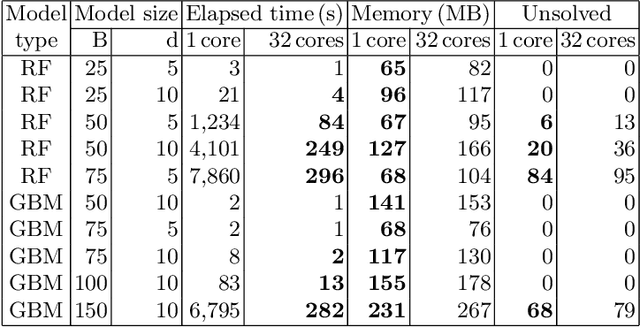
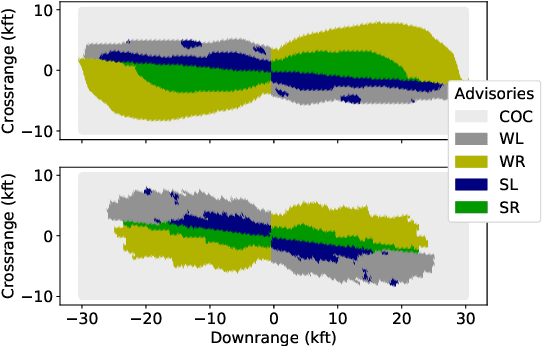
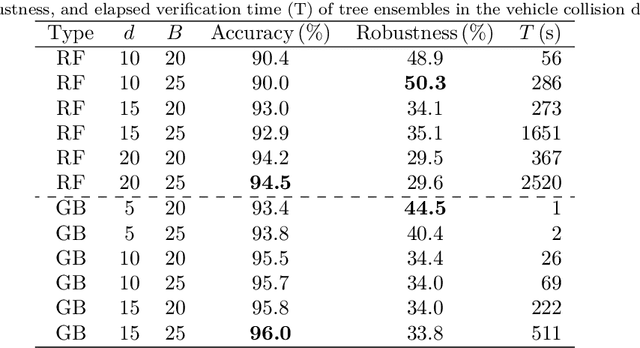
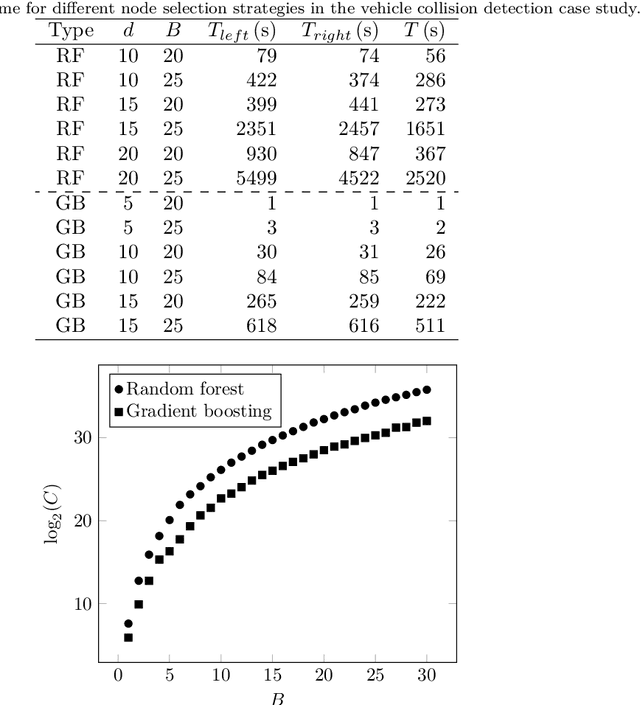
To guarantee that machine learning models yield outputs that are not only accurate, but also robust, recent works propose formally verifying robustness properties of machine learning models. To be applicable to realistic safety-critical systems, the used verification algorithms need to manage the combinatorial explosion resulting from vast variations in the input domain, and be able to verify correctness properties derived from versatile and domain-specific requirements. In this paper, we formalise the VoTE algorithm presented earlier as a tool description, and extend the tool set with mechanisms for systematic scalability studies. In particular, we show a) how the separation of property checking from the core verification engine enables verification of versatile requirements, b) the scalability of the tool, both in terms of time taken for verification and use of memory, and c) that the algorithm has attractive properties that lend themselves well for massive parallelisation. We demonstrate the application of the tool in two case studies, namely digit recognition and aircraft collision avoidance, where the first case study serves to assess the resource utilisation of the tool, and the second to assess the ability to verify versatile correctness properties.
Formal Verification of Input-Output Mappings of Tree Ensembles
May 10, 2019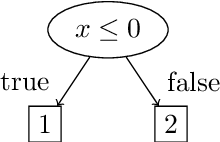

Recent advances in machine learning and artificial intelligence are now being considered in safety-critical autonomous systems where software defects may cause severe harm to humans and the environment. Design organizations in these domains are currently unable to provide convincing arguments that their systems are safe to operate when machine learning algorithms are used to implement their software. In this paper, we present an efficient method to extract equivalence classes from decision trees and tree ensembles, and to formally verify that their input-output mappings comply with requirements. The idea is that, given that safety requirements can be traced to desirable properties on system input-output patterns, we can use positive verification outcomes in safety arguments. This paper presents the implementation of the method in the tool VoTE (Verifier of Tree Ensembles), and evaluates its scalability on two case studies presented in current literature. We demonstrate that our method is practical for tree ensembles trained on low-dimensional data with up to 25 decision trees and tree depths of up to 20. Our work also studies the limitations of the method with high-dimensional data and preliminarily investigates the trade-off between large number of trees and time taken for verification.