 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Recognition Through Visual and Acoustic Cues Using K-Means
Nov 26, 2018

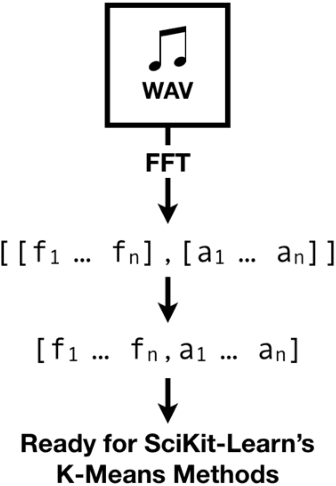

We propose a K-Means based prediction system, nicknamed SERVANT (Scene Recognition Through Visual and Acoustic Cues), that is capable of recognizing environmental scenes through analysis of ambient sound and color cues. The concept and implementation originated within the Learning branch of the Intelligent Wearable Robotics Project (also known as the Third Arm project) at the Stanford Artificial Intelligence Lab-Toyota Center (SAIL-TC). The Third Arm Project focuses on the development and conceptualization of a robotic arm that can aid users in a whole array of situations: i.e. carrying a cup of coffee, holding a flashlight. Servant uses a K-Means fit-and-predict architecture to classify environmental scenes, such as that of a coffee shop or a basketball gym, using visual and auditory cues. Following such classification, Servant can recommend contextual actions based on prior training.