 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouterKT: Mixture-of-Experts for Knowledge Tracing
Apr 11, 2025

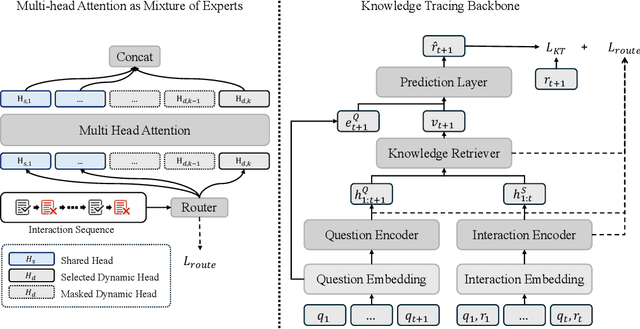

Knowledge Tracing (KT) is a fundamental task in Intelligent Tutoring Systems (ITS), which aims to model the dynamic knowledge states of students based on their interaction histories. However, existing KT models often rely on a global forgetting decay mechanism for capturing learning patterns, assuming that students' performance is predominantly influenced by their most recent interactions. Such approaches fail to account for the diverse and complex learning patterns arising from individual differences and varying learning stages. To address this limitation, we propose RouterKT, a novel Mixture-of-Experts (MoE) architecture designed to capture heterogeneous learning patterns by enabling experts to specialize in different patterns without any handcrafted learning pattern bias such as forgetting decay. Specifically, RouterKT introduces a \textbf{person-wise routing mechanism} to effectively model individual-specific learning behaviors and employs \textbf{multi-heads as experts} to enhance the modeling of complex and diverse patterns. Comprehensive experiments on ten benchmark datasets demonstrate that RouterKT exhibits significant flexibility and improves the performance of various KT backbone models, with a maximum average AUC improvement of 3.29\% across different backbones and datasets, outperforming other state-of-the-art models. Moreover, RouterKT demonstrates consistently superior inference efficiency compared to existing approaches based on handcrafted learning pattern bias, highlighting its usability for real-world educational applications. The source code is available at https://github.com/derek-liao/RouterKT.git.
Fair Knowledge Tracing in Second Language Acquisition
Dec 23, 2024



In second-language acquisition, predictive modeling aids educators in implementing diverse teaching strategies, attracting significant research attention. However, while model accuracy is widely explored, model fairness remains under-examined. Model fairness ensures equitable treatment of groups, preventing unintentional biases based on attributes such as gender, ethnicity, or economic background. A fair model should produce impartial outcomes that do not systematically disadvantage any group. This study evaluates the fairness of two predictive models using the Duolingo dataset's en\_es (English learners speaking Spanish), es\_en (Spanish learners speaking English), and fr\_en (French learners speaking English) tracks. We analyze: 1. Algorithmic fairness across platforms (iOS, Android, Web). 2. Algorithmic fairness between developed and developing countries. Key findings include: 1. Deep learning outperforms machine learning in second-language knowledge tracing due to improved accuracy and fairness. 2. Both models favor mobile users over non-mobile users. 3. Machine learning exhibits stronger bias against developing countries compared to deep learning. 4. Deep learning strikes a better balance of fairness and accuracy in the en\_es and es\_en tracks, while machine learning is more suitable for fr\_en. This study highlights the importance of addressing fairness in predictive models to ensure equitable educational strategies across platforms and regions.