 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Transfer Learning for Improving Domain-Specific Search Experience Using Query to Question Similarity
Jan 07, 2021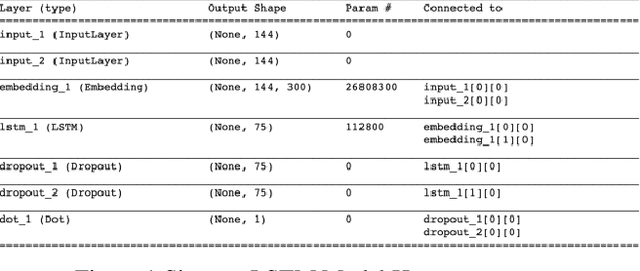
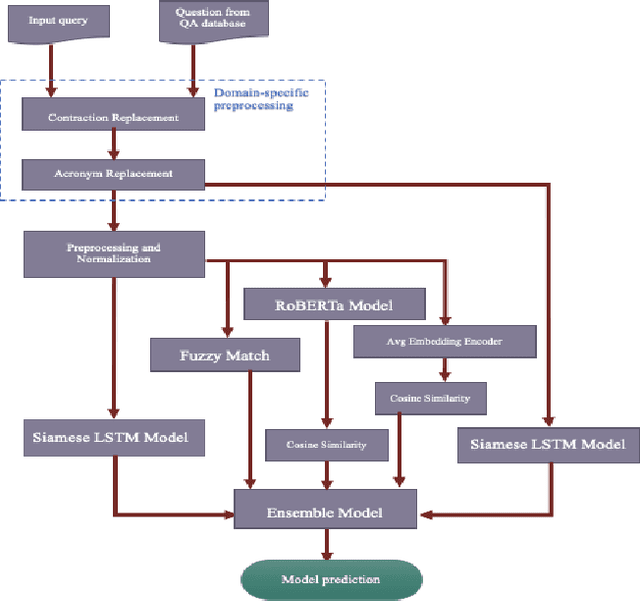
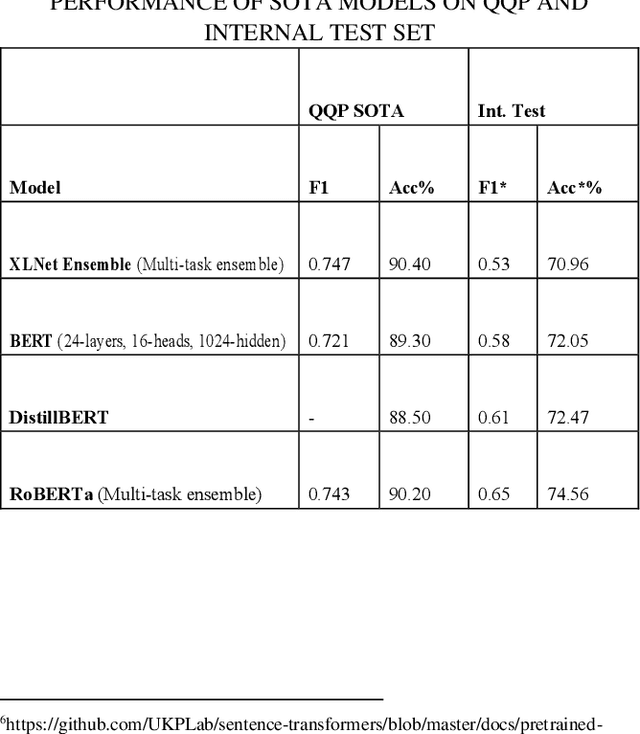

Search is one of the most common platforms used to seek information. However, users mostly get overloaded with results whenever they use such a platform to resolve their queries. Nowadays, direct answers to queries are being provided as a part of the search experience. The question-answer (QA) retrieval process plays a significant role in enriching the search experience. Most off-the-shelf Semantic Textual Similarity models work fine for well-formed search queries, but their performances degrade when applied to a domain-specific setting having incomplete or grammatically ill-formed search queries in prevalence. In this paper, we discuss a framework for calculating similarities between a given input query and a set of predefined questions to retrieve the question which matches to it the most. We have used it for the financial domain, but the framework is generalized for any domain-specific search engine and can be used in other domains as well. We use Siamese network [6] over Long Short-Term Memory (LSTM) [3] models to train a classifier which generates unnormalized and normalized similarity scores for a given pair of questions. Moreover, for each of these question pairs, we calculate three other similarity scores: cosine similarity between their average word2vec embeddings [15], cosine similarity between their sentence embeddings [7] generated using RoBERTa [17] and their customized fuzzy-match score. Finally, we develop a metaclassifier using Support Vector Machines [19] for combining these five scores to detect if a given pair of questions is similar. We benchmark our model's performance against existing State Of The Art (SOTA) models on Quora Question Pairs (QQP) dataset as well as a dataset specific to the financial domain.