 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptHive: Bringing Subject Matter Experts Back to the Forefront with Collaborative Prompt Engineering for Educational Content Creation
Oct 21, 2024


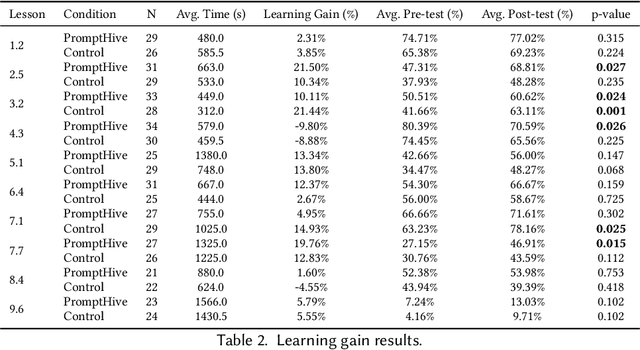
Involving subject matter experts in prompt engineering can guide LLM outputs toward more helpful, accurate, and tailored content that meets the diverse needs of different domains. However, iterating towards effective prompts can be challenging without adequate interface support for systematic experimentation within specific task contexts. In this work, we introduce PromptHive, a collaborative interface for prompt authoring, designed to better connect domain knowledge with prompt engineering through features that encourage rapid iteration on prompt variations. We conducted an evaluation study with ten subject matter experts in math and validated our design through two collaborative prompt-writing sessions and a learning gain study with 358 learners. Our results elucidate the prompt iteration process and validate the tool's usability, enabling non-AI experts to craft prompts that generate content comparable to human-authored materials while reducing perceived cognitive load by half and shortening the authoring process from several months to just a few hours.
Leveraging LLM-Respondents for Item Evaluation: a Psychometric Analysis
Jul 15, 2024

Effective educational measurement relies heavily on the curation of well-designed item pools (i.e., possessing the right psychometric properties). However, item calibration is time-consuming and costly, requiring a sufficient number of respondents for the response process. We explore using six different LLMs (GPT-3.5, GPT-4, Llama 2, Llama 3, Gemini-Pro, and Cohere Command R Plus) and various combinations of them using sampling methods to produce responses with psychometric properties similar to human answers. Results show that some LLMs have comparable or higher proficiency in College Algebra than college students. No single LLM mimics human respondents due to narrow proficiency distributions, but an ensemble of LLMs can better resemble college students' ability distribution. The item parameters calibrated by LLM-Respondents have high correlations (e.g. > 0.8 for GPT-3.5) compared to their human calibrated counterparts, and closely resemble the parameters of the human subset (e.g. 0.02 Spearman correlation difference). Several augmentation strategies are evaluated for their relative performance, with resampling methods proving most effective, enhancing the Spearman correlation from 0.89 (human only) to 0.93 (augmented human).
Learning gain differences between ChatGPT and human tutor generated algebra hints
Feb 14, 2023



Large Language Models (LLMs), such as ChatGPT, are quickly advancing AI to the frontiers of practical consumer use and leading industries to re-evaluate how they allocate resources for content production. Authoring of open educational resources and hint content within adaptive tutoring systems is labor intensive. Should LLMs like ChatGPT produce educational content on par with human-authored content, the implications would be significant for further scaling of computer tutoring system approaches. In this paper, we conduct the first learning gain evaluation of ChatGPT by comparing the efficacy of its hints with hints authored by human tutors with 77 participants across two algebra topic areas, Elementary Algebra and Intermediate Algebra. We find that 70% of hints produced by ChatGPT passed our manual quality checks and that both human and ChatGPT conditions produced positive learning gains. However, gains were only statistically significant for human tutor created hints. Learning gains from human-created hints were substantially and statistically significantly higher than ChatGPT hints in both topic areas, though ChatGPT participants in the Intermediate Algebra experiment were near ceiling and not even with the control at pre-test. We discuss the limitations of our study and suggest several future directions for the field. Problem and hint content used in the experiment is provided for replicability.