 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangent-Space Gradient Optimization of Tensor Network for Machine Learning
Jan 10, 2020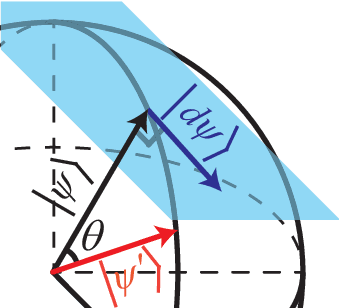
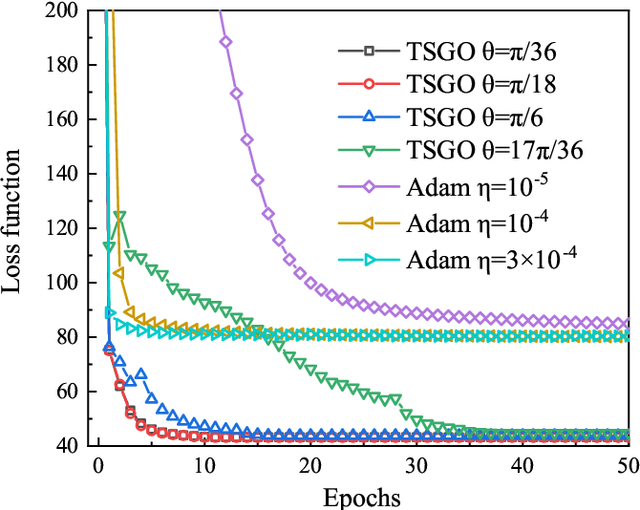
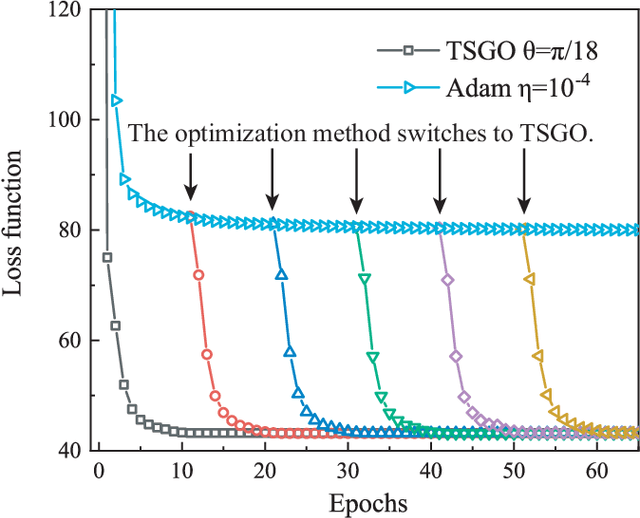
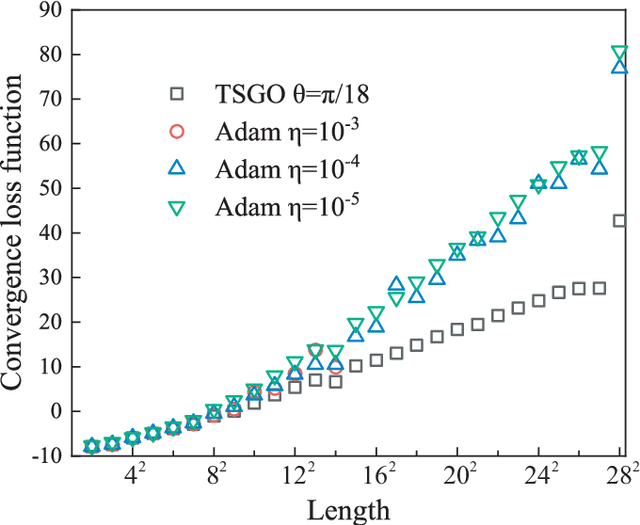
The gradient-based optimization method for deep machine learning models suffers from gradient vanishing and exploding problems, particularly when the computational graph becomes deep. In this work, we propose the tangent-space gradient optimization (TSGO) for the probabilistic models to keep the gradients from vanishing or exploding. The central idea is to guarantee the orthogonality between the variational parameters and the gradients. The optimization is then implemented by rotating parameter vector towards the direction of gradient. We explain and testify TSGO in tensor network (TN) machine learning, where the TN describes the joint probability distribution as a normalized state $\left| \psi \right\rangle $ in Hilbert space. We show that the gradient can be restricted in the tangent space of $\left\langle \psi \right.\left| \psi \right\rangle = 1$ hyper-sphere. Instead of additional adaptive methods to control the learning rate in deep learning, the learning rate of TSGO is naturally determined by the angle $\theta $ as $\eta = \tan \theta $. Our numerical results reveal better convergence of TSGO in comparison to the off-the-shelf Adam.