 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigation Instruction Generation with BEV Perception and Large Language Models
Jul 21, 2024

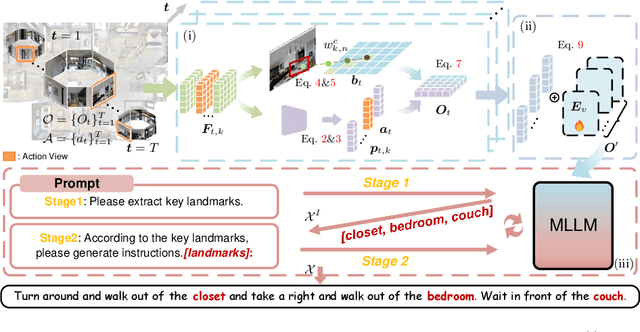

Navigation instruction generation, which requires embodied agents to describe the navigation routes, has been of great interest in robotics and human-computer interaction. Existing studies directly map the sequence of 2D perspective observations to route descriptions. Though straightforward, they overlook the geometric information and object semantics of the 3D environment. To address these challenges, we propose BEVInstructor, which incorporates Bird's Eye View (BEV) features into Multi-Modal Large Language Models (MLLMs) for instruction generation. Specifically, BEVInstructor constructs a PerspectiveBEVVisual Encoder for the comprehension of 3D environments through fusing BEV and perspective features. To leverage the powerful language capabilities of MLLMs, the fused representations are used as visual prompts for MLLMs, and perspective-BEV prompt tuning is proposed for parameter-efficient updating. Based on the perspective-BEV prompts, BEVInstructor further adopts an instance-guided iterative refinement pipeline, which improves the instructions in a progressive manner. BEVInstructor achieves impressive performance across diverse datasets (i.e., R2R, REVERIE, and UrbanWalk).