 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Mispronunciation detection system using a hybrid CTC-ATT based approach for L2 English speakers
Jan 25, 2022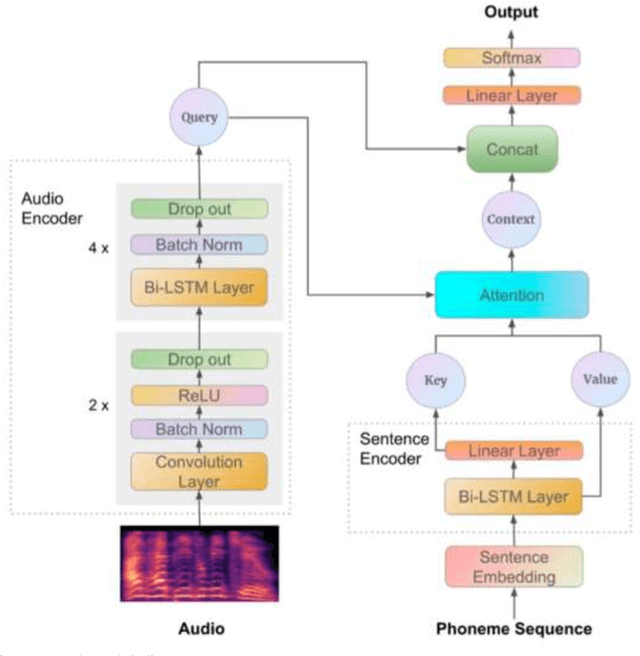
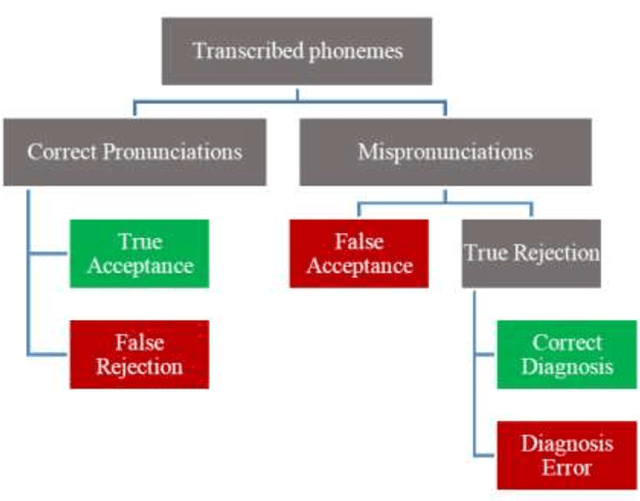
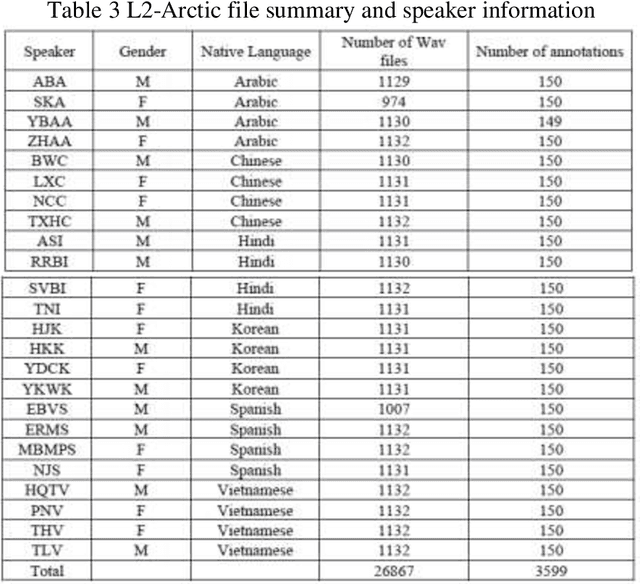
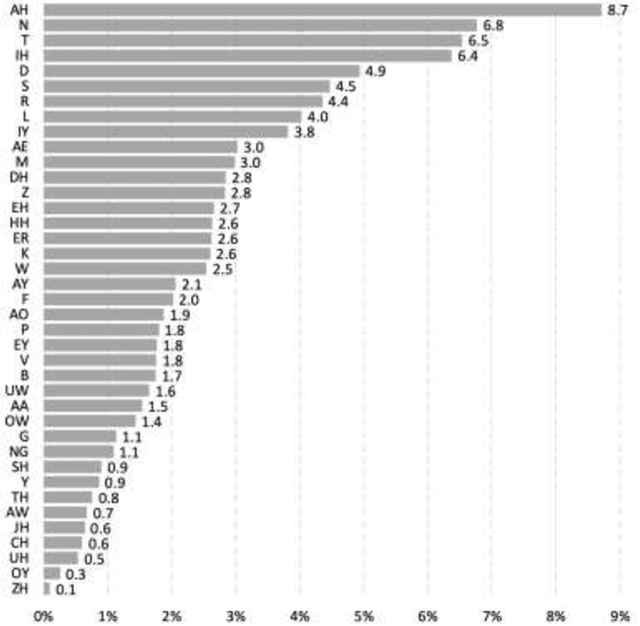
This report proposes state-of-the-art research in the field of Computer Assisted Language Learning (CALL). Mispronunciation detection is one of the core components of Computer Assisted Pronunciation Training (CAPT) systems which is a subset of CALL. Studies on automated pronunciation error detection began in the 1990s, but the development of fullfledged CAPTs has only accelerated in the last decade due to an increase in computing power and availability of mobile devices for recording speech required for pronunciation analysis. Detecting Pronunciation errors is a hard problem to solve as there is no formal definition of correct and incorrect pronunciation. As a result, typically prosodic and phoneme errors such as phoneme substitution, insertion, and deletion are detected. Also, it has been agreed upon that learning pronunciation should focus on speaker intelligibility rather than sounding like an L1 English speaker. Initially, methods were developed on posterior likelihood called Good of Pronunciation using Gaussian Mixture Model-Hidden Markov Model and Deep Neural Network-Hidden Markov Model approaches. These are complex systems to implement when compared with the recently proposed ASR based End-to-End mispronunciations detection systems. The purpose of this research is to create End-to-End (E2E) models using Connectionist Temporal Classification (CTC) and Attention-based sequence decoder. Recently, E2E models have shown considerable improvement in mispronunciation detection accuracy. This research will draw comparison amongst baseline models CNN-RNN-CTC, CNN-RNN-CTC with character sequence-based attention decoder, and CNN-RNN-CTC with phoneme-based decoder systems. This study will help us in deciding a better approach towards developing an efficient mispronunciation detection system.