 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Character Similarity with Vision Transformers
May 24, 2023Record linkage is a bedrock of quantitative social science, as analyses often require linking data from multiple, noisy sources. Off-the-shelf string matching methods are widely used, as they are straightforward and cheap to implement and scale. Not all character substitutions are equally probable, and for some settings there are widely used handcrafted lists denoting which string substitutions are more likely, that improve the accuracy of string matching. However, such lists do not exist for many settings, skewing research with linked datasets towards a few high-resource contexts that are not representative of the diversity of human societies. This study develops an extensible way to measure character substitution costs for OCR'ed documents, by employing large-scale self-supervised training of vision transformers (ViT) with augmented digital fonts. For each language written with the CJK script, we contrastively learn a metric space where different augmentations of the same character are represented nearby. In this space, homoglyphic characters - those with similar appearance such as ``O'' and ``0'' - have similar vector representations. Using the cosine distance between characters' representations as the substitution cost in an edit distance matching algorithm significantly improves record linkage compared to other widely used string matching methods, as OCR errors tend to be homoglyphic in nature. Homoglyphs can plausibly capture character visual similarity across any script, including low-resource settings. We illustrate this by creating homoglyph sets for 3,000 year old ancient Chinese characters, which are highly pictorial. Fascinatingly, a ViT is able to capture relationships in how different abstract concepts were conceptualized by ancient societies, that have been noted in the archaeological literature.
Linking Representations with Multimodal Contrastive Learning
Apr 11, 2023
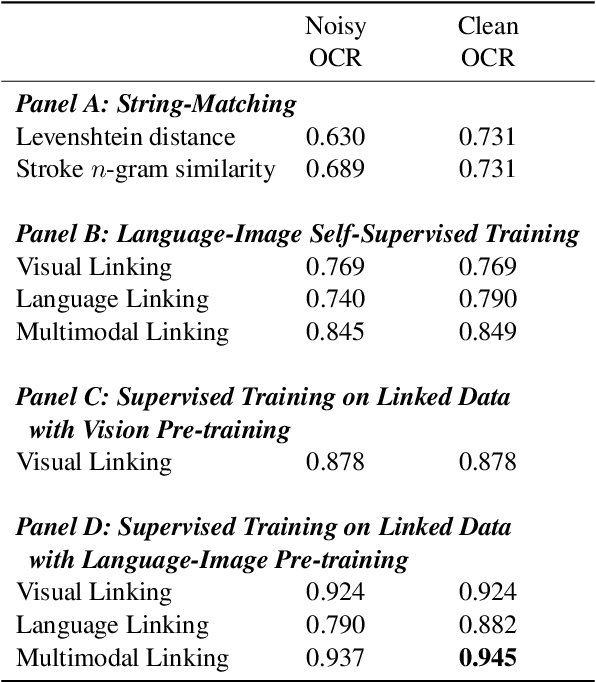
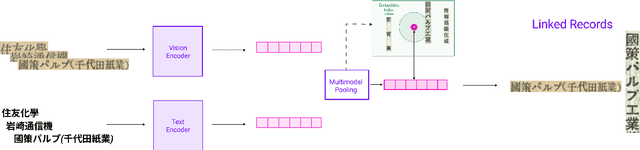
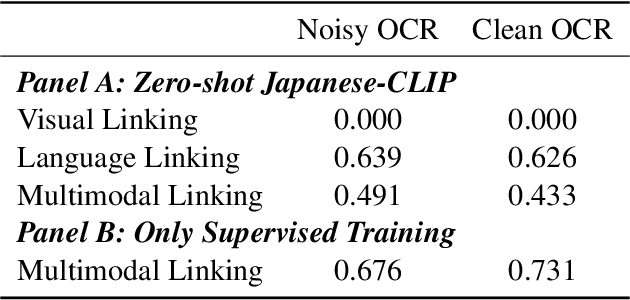
Many applications require grouping instances contained in diverse document datasets into classes. Most widely used methods do not employ deep learning and do not exploit the inherently multimodal nature of documents. Notably, record linkage is typically conceptualized as a string-matching problem. This study develops CLIPPINGS, (Contrastively Linking Pooled Pre-trained Embeddings), a multimodal framework for record linkage. CLIPPINGS employs end-to-end training of symmetric vision and language bi-encoders, aligned through contrastive language-image pre-training, to learn a metric space where the pooled image-text representation for a given instance is close to representations in the same class and distant from representations in different classes. At inference time, instances can be linked by retrieving their nearest neighbor from an offline exemplar embedding index or by clustering their representations. The study examines two challenging applications: constructing comprehensive supply chains for mid-20th century Japan through linking firm level financial records - with each firm name represented by its crop in the document image and the corresponding OCR - and detecting which image-caption pairs in a massive corpus of historical U.S. newspapers came from the same underlying photo wire source. CLIPPINGS outperforms widely used string matching methods by a wide margin and also outperforms unimodal methods. Moreover, a purely self-supervised model trained on only image-OCR pairs also outperforms popular string-matching methods without requiring any labels.