 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextPixs: Glyph-Conditioned Diffusion with Character-Aware Attention and OCR-Guided Supervision
Jul 08, 2025The modern text-to-image diffusion models boom has opened a new era in digital content production as it has proven the previously unseen ability to produce photorealistic and stylistically diverse imagery based on the semantics of natural-language descriptions. However, the consistent disadvantage of these models is that they cannot generate readable, meaningful, and correctly spelled text in generated images, which significantly limits the use of practical purposes like advertising, learning, and creative design. This paper introduces a new framework, namely Glyph-Conditioned Diffusion with Character-Aware Attention (GCDA), using which a typical diffusion backbone is extended by three well-designed modules. To begin with, the model has a dual-stream text encoder that encodes both semantic contextual information and explicit glyph representations, resulting in a character-aware representation of the input text that is rich in nature. Second, an attention mechanism that is aware of the character is proposed with a new attention segregation loss that aims to limit the attention distribution of each character independently in order to avoid distortion artifacts. Lastly, GCDA has an OCR-in-the-loop fine-tuning phase, where a full text perceptual loss, directly optimises models to be legible and accurately spell. Large scale experiments to benchmark datasets, such as MARIO-10M and T2I-CompBench, reveal that GCDA sets a new state-of-the-art on all metrics, with better character based metrics on text rendering (Character Error Rate: 0.08 vs 0.21 for the previous best; Word Error Rate: 0.15 vs 0.25), human perception, and comparable image synthesis quality on high-fidelity (FID: 14.3).
AttentionDrop: A Novel Regularization Method for Transformer Models
Apr 16, 2025



Transformer-based architectures achieve state-of-the-art performance across a wide range of tasks in natural language processing, computer vision, and speech. However, their immense capacity often leads to overfitting, especially when training data is limited or noisy. We propose AttentionDrop, a unified family of stochastic regularization techniques that operate directly on the self-attention distributions. We introduces three variants: 1. Hard Attention Masking: randomly zeroes out top-k attention logits per query to encourage diverse context utilization. 2. Blurred Attention Smoothing: applies a dynamic Gaussian convolution over attention logits to diffuse overly peaked distributions. 3. Consistency-Regularized AttentionDrop: enforces output stability under multiple independent AttentionDrop perturbations via a KL-based consistency loss.
AI-based Wearable Vision Assistance System for the Visually Impaired: Integrating Real-Time Object Recognition and Contextual Understanding Using Large Vision-Language Models
Dec 28, 2024Visual impairment affects the ability of people to live a life like normal people. Such people face challenges in performing activities of daily living, such as reading, writing, traveling and participating in social gatherings. Many traditional approaches are available to help visually impaired people; however, these are limited in obtaining contextually rich environmental information necessary for independent living. In order to overcome this limitation, this paper introduces a novel wearable vision assistance system that has a hat-mounted camera connected to a Raspberry Pi 4 Model B (8GB RAM) with artificial intelligence (AI) technology to deliver real-time feedback to a user through a sound beep mechanism. The key features of this system include a user-friendly procedure for the recognition of new people or objects through a one-click process that allows users to add data on new individuals and objects for later detection, enhancing the accuracy of the recognition over time. The system provides detailed descriptions of objects in the user's environment using a large vision language model (LVLM). In addition, it incorporates a distance sensor that activates a beeping sound using a buzzer as soon as the user is about to collide with an object, helping to ensure safety while navigating their environment. A comprehensive evaluation is carried out to evaluate the proposed AI-based solution against traditional support techniques. Comparative analysis shows that the proposed solution with its innovative combination of hardware and AI (including LVLMs with IoT), is a significant advancement in assistive technology that aims to solve the major issues faced by the community of visually impaired people
A Hybrid Approach for COVID-19 Detection: Combining Wasserstein GAN with Transfer Learning
Nov 18, 2024COVID-19 is extremely contagious and its rapid growth has drawn attention towards its early diagnosis. Early diagnosis of COVID-19 enables healthcare professionals and government authorities to break the chain of transition and flatten the epidemic curve. With the number of cases accelerating across the developed world, COVID-19 induced Viral Pneumonia cases is a big challenge. Overlapping of COVID-19 cases with Viral Pneumonia and other lung infections with limited dataset and long training hours is a serious problem to cater. Limited amount of data often results in over-fitting models and due to this reason, model does not predict generalized results. To fill this gap, we proposed GAN-based approach to synthesize images which later fed into the deep learning models to classify images of COVID-19, Normal, and Viral Pneumonia. Specifically, customized Wasserstein GAN is proposed to generate 19% more Chest X-ray images as compare to the real images. This expanded dataset is then used to train four proposed deep learning models: VGG-16, ResNet-50, GoogLeNet and MNAST. The result showed that expanded dataset utilized deep learning models to deliver high classification accuracies. In particular, VGG-16 achieved highest accuracy of 99.17% among all four proposed schemes. Rest of the models like ResNet-50, GoogLeNet and MNAST delivered 93.9%, 94.49% and 97.75% testing accuracies respectively. Later, the efficiency of these models is compared with the state of art models on the basis of accuracy. Further, our proposed models can be applied to address the issue of scant datasets for any problem of image analysis.
Artificial Intelligence For Breast Cancer Detection: Trends & Directions
Oct 03, 2021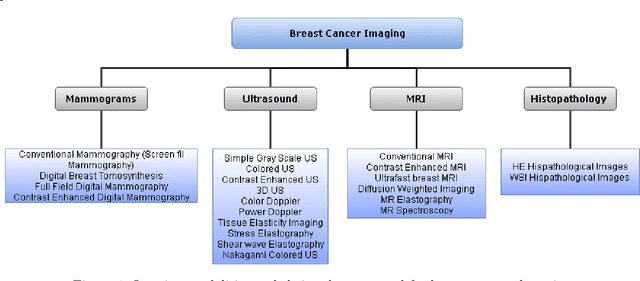
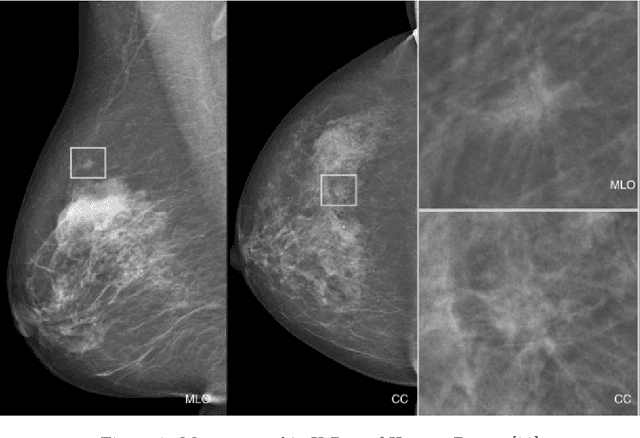
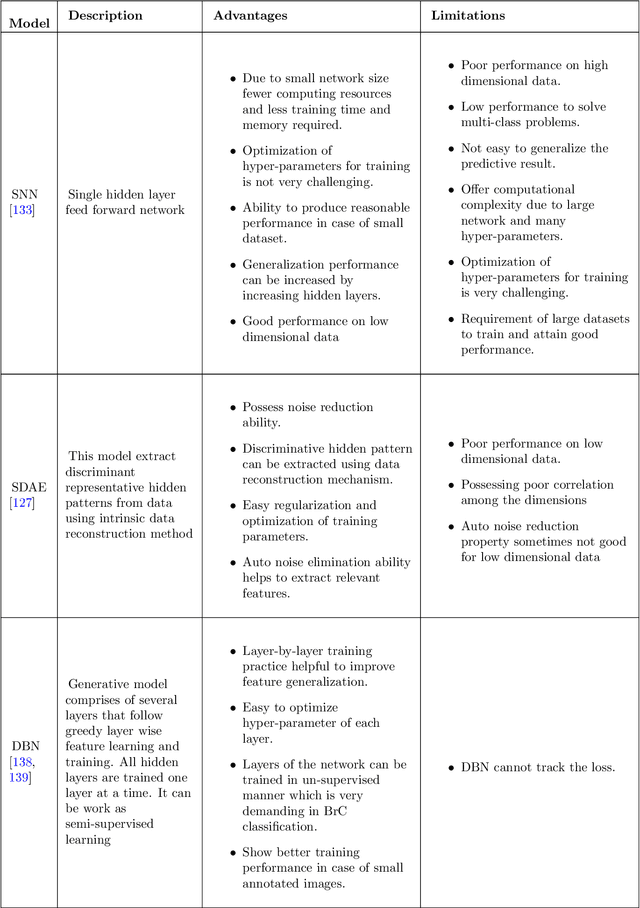
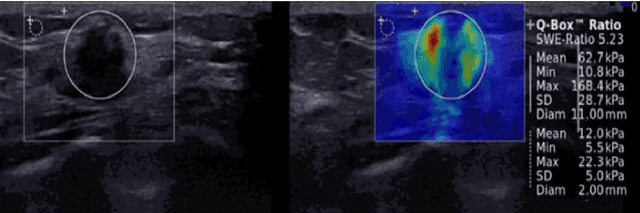
In the last decade, researchers working in the domain of computer vision and Artificial Intelligence (AI) have beefed up their efforts to come up with the automated framework that not only detects but also identifies stage of breast cancer. The reason for this surge in research activities in this direction are mainly due to advent of robust AI algorithms (deep learning), availability of hardware that can train those robust and complex AI algorithms and accessibility of large enough dataset required for training AI algorithms. Different imaging modalities that have been exploited by researchers to automate the task of breast cancer detection are mammograms, ultrasound, magnetic resonance imaging, histopathological images or any combination of them. This article analyzes these imaging modalities and presents their strengths, limitations and enlists resources from where their datasets can be accessed for research purpose. This article then summarizes AI and computer vision based state-of-the-art methods proposed in the last decade, to detect breast cancer using various imaging modalities. Generally, in this article we have focused on to review frameworks that have reported results using mammograms as it is most widely used breast imaging modality that serves as first test that medical practitioners usually prescribe for the detection of breast cancer. Second reason of focusing on mammogram imaging modalities is the availability of its labeled datasets. Datasets availability is one of the most important aspect for the development of AI based frameworks as such algorithms are data hungry and generally quality of dataset affects performance of AI based algorithms. In a nutshell, this research article will act as a primary resource for the research community working in the field of automated breast imaging analysis.