 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnifont Persian OCR System Using Primitives
Feb 13, 2022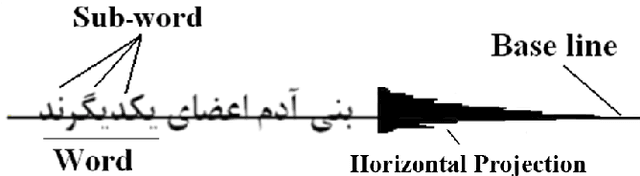
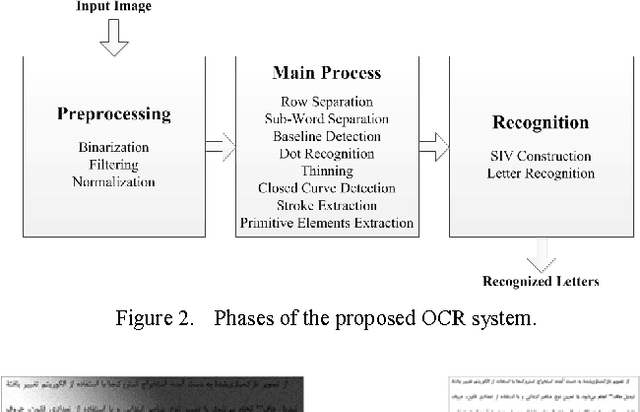


In this paper, we introduce a model-based omnifont Persian OCR system. The system uses a set of 8 primitive elements as structural features for recognition. First, the scanned document is preprocessed. After normalizing the preprocessed image, text rows and sub-words are separated and then thinned. After recognition of dots in sub-words, strokes are extracted and primitive elements of each sub-word are recognized using the strokes. Finally, the primitives are compared with a predefined set of character identification vectors in order to identify sub-word characters. The separation and recognition steps of the system are concurrent, eliminating unavoidable errors of independent separation of letters. The system has been tested on documents with 14 standard Persian fonts in 6 sizes. The achieved precision is 97.06%.