 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrune2Edge: A Multi-Phase Pruning Pipelines to Deep Ensemble Learning in IIoT
Apr 09, 2020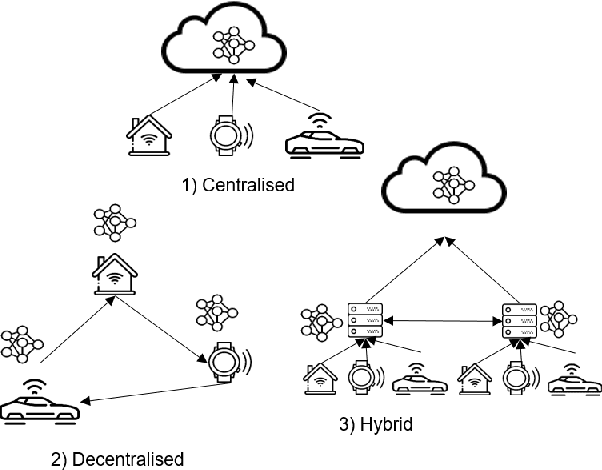
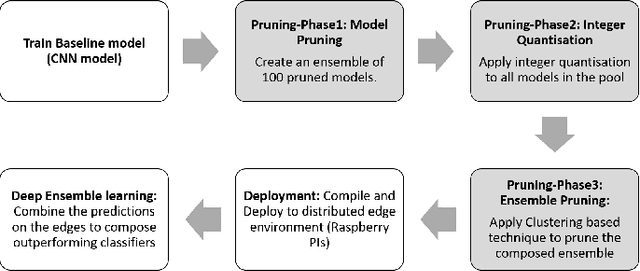

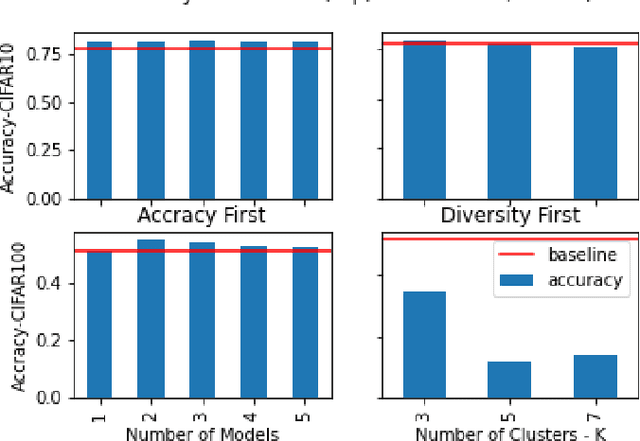
Most recently, with the proliferation of IoT devices, computational nodes in manufacturing systems IIoT(Industrial-Internet-of-things) and the lunch of 5G networks, there will be millions of connected devices generating a massive amount of data. In such an environment, the controlling systems need to be intelligent enough to deal with a vast amount of data to detect defects in a real-time process. Driven by such a need, artificial intelligence models such as deep learning have to be deployed into IIoT systems. However, learning and using deep learning models are computationally expensive, so an IoT device with limited computational power could not run such models. To tackle this issue, edge intelligence had emerged as a new paradigm towards running Artificial Intelligence models on edge devices. Although a considerable amount of studies have been proposed in this area, the research is still in the early stages. In this paper, we propose a novel edge-based multi-phase pruning pipelines to ensemble learning on IIoT devices. In the first phase, we generate a diverse ensemble of pruned models, then we apply integer quantisation, next we prune the generated ensemble using a clustering-based technique. Finally, we choose the best representative from each generated cluster to be deployed to a distributed IoT environment. On CIFAR-100 and CIFAR-10, our proposed approach was able to outperform the predictability levels of a baseline model (up to 7%), more importantly, the generated learners have small sizes (up to 90% reduction in the model size) that minimise the required computational capabilities to make an inference on the resource-constraint devices.
EnSyth: A Pruning Approach to Synthesis of Deep Learning Ensembles
Jul 22, 2019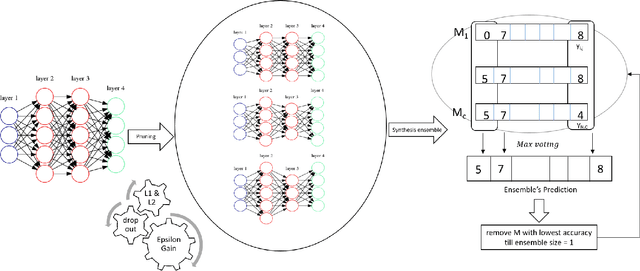
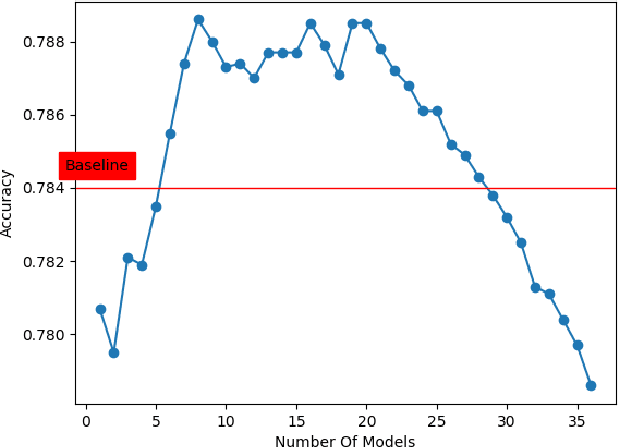
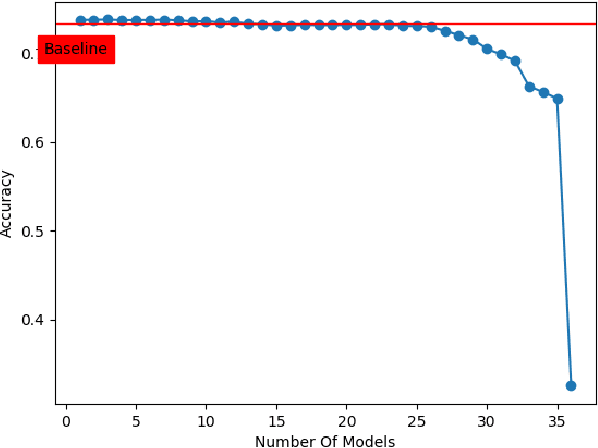
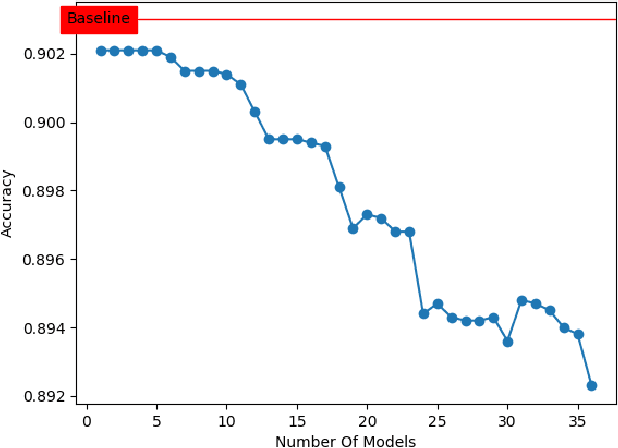
Deep neural networks have achieved state-of-art performance in many domains including computer vision, natural language processing and self-driving cars. However, they are very computationally expensive and memory intensive which raises significant challenges when it comes to deploy or train them on strict latency applications or resource-limited environments. As a result, many attempts have been introduced to accelerate and compress deep learning models, however the majority were not able to maintain the same accuracy of the baseline models. In this paper, we describe EnSyth, a deep learning ensemble approach to enhance the predictability of compact neural network's models. First, we generate a set of diverse compressed deep learning models using different hyperparameters for a pruning method, after that we utilise ensemble learning to synthesise the outputs of the compressed models to compose a new pool of classifiers. Finally, we apply backward elimination on the generated pool to explore the best performing combinations of models. On CIFAR-10, CIFAR-5 data-sets with LeNet-5, EnSyth outperforms the predictability of the baseline model.