 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Learning to Operationalize a Domain Agnostic Data Quality Scoring
Aug 16, 2021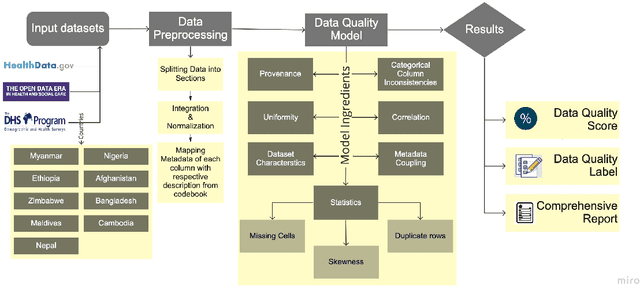

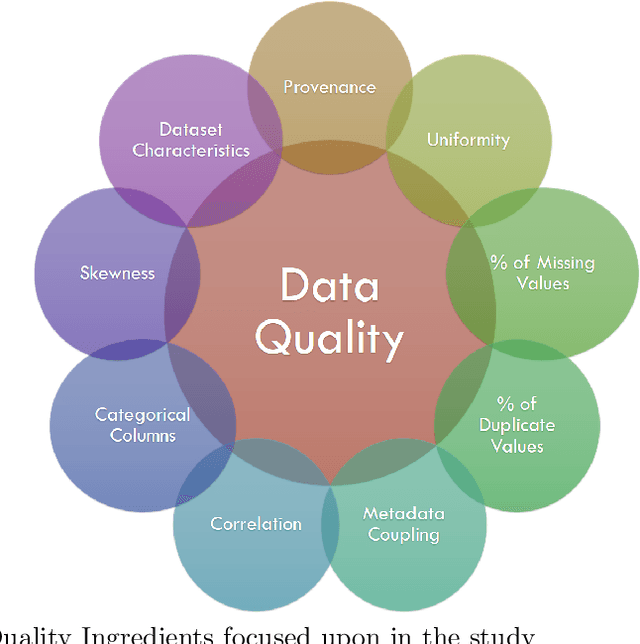
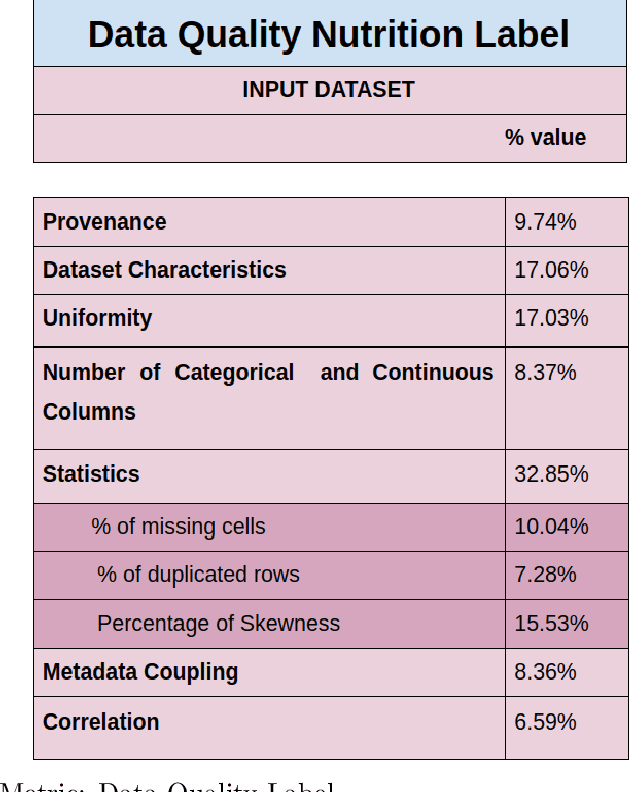
Data is expanding at an unimaginable rate, and with this development comes the responsibility of the quality of data. Data Quality refers to the relevance of the information present and helps in various operations like decision making and planning in a particular organization. Mostly data quality is measured on an ad-hoc basis, and hence none of the developed concepts provide any practical application. The current empirical study was undertaken to formulate a concrete automated data quality platform to assess the quality of incoming dataset and generate a quality label, score and comprehensive report. We utilize various datasets from healthdata.gov, opendata.nhs and Demographics and Health Surveys (DHS) Program to observe the variations in the quality score and formulate a label using Principal Component Analysis(PCA). The results of the current empirical study revealed a metric that encompasses nine quality ingredients, namely provenance, dataset characteristics, uniformity, metadata coupling, percentage of missing cells and duplicate rows, skewness of data, the ratio of inconsistencies of categorical columns, and correlation between these attributes. The study also provides an illustrative case study and validation of the metric following Mutation Testing approaches. This research study provides an automated platform which takes an incoming dataset and metadata to provide the DQ score, report and label. The results of this study would be useful to data scientists as the value of this quality label would instill confidence before deploying the data for his/her respective practical application.