 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Balanced Cross Entropy Loss for Medical Image Segmentation
Dec 08, 2024



A novel method for tackling the problem of imbalanced data in medical image segmentation is proposed in this work. In balanced cross entropy (CE) loss, which is a type of weighted CE loss, the weight assigned to each class is the in-verse of the class frequency. These balancing weights are expected to equalize the effect of each class on the overall loss and prevent the model from being biased towards the majority class. But, as it has been shown in previous studies, this method degrades the performance by a large margin. Therefore, balanced CE is not a popular loss in medical segmentation tasks, and usually a region-based loss, like the Dice loss, is used to address the class imbalance problem. In the pro-posed method, the weighting of cross entropy loss for each class is based on a dilated area of each class mask, and balancing weights are assigned to each class together with its surrounding pixels. The goal of this study is to show that the performance of balanced CE loss can be greatly improved my modifying its weighting strategy. Experiments on different datasets show that the proposed dilated balanced CE (DBCE) loss outperforms the balanced CE loss by a large margin and produces superior results compared to CE loss, and its performance is similar to the performance of the combination of Dice and CE loss. This means that a weighted cross entropy loss with the right weighing strategy can be as effective as a region-based loss in handling the problem of class imbalance in medical segmentation tasks.
Lattice Fusion Networks for Image Denoising
Nov 28, 2020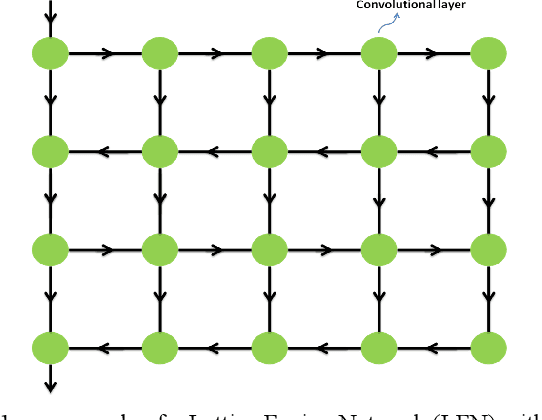

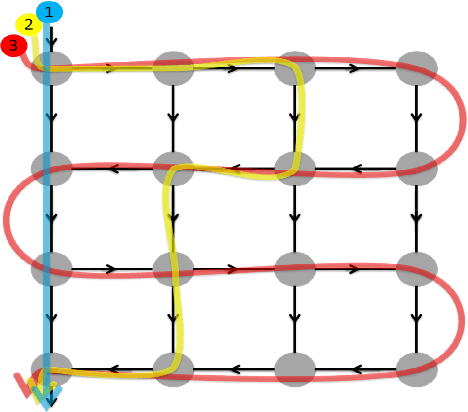
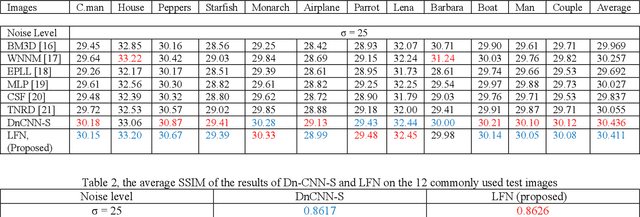
A novel method for feature fusion in convolutional neural networks is proposed in this work. Different feature fusion techniques are suggested to facilitate the flow of information and improve the training of deep neural networks. Some of these techniques as well as the proposed model can be considered a type of Directed Acyclic Graph (DAG) Network, where a layer can receive inputs from other layers and have outputs to other layers. In the proposed general framework of Lattice Fusion Network (LFN), feature maps of each convolutional layer are passed to other layers based on a lattice graph structure, where nodes are convolutional layers. To investigate the performance of the model, a specific design based on the general framework of LFN is implemented for image denoising. Results are compared with state of the art methods. The proposed model produced competitive results with far fewer learnable parameters, which shows the effectiveness of LFNs for training of deep neural networks
Image Denoising for Strong Gaussian Noises With Specialized CNNs for Different Frequency Components
Nov 26, 2020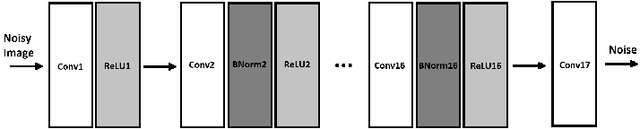
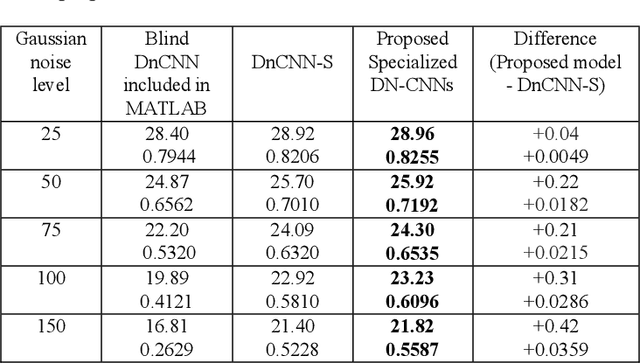

In machine learning approach to image denoising a network is trained to recover a clean image from a noisy one. In this paper a novel structure is proposed based on training multiple specialized networks as opposed to existing structures that are base on a single network. The proposed model is an alternative for training a very deep network to avoid issues like vanishing or exploding gradient. By dividing a very deep network into two smaller networks the same number of learnable parameters will be available, but two smaller networks should be trained which are easier to train. Over smoothing and waxy artifacts are major problems with existing methods; because the network tries to keep the Mean Square Error (MSE) low for general structures and details, which leads to overlooking of details. This problem is more severe in the presence of strong noise. To reduce this problem, in the proposed structure, the image is decomposed into its low and high frequency components and each component is used to train a separate denoising convolutional neural network. One network is specialized to reconstruct the general structure of the image and the other one is specialized to reconstruct the details. Results of the proposed method show higher peak signal to noise ratio (PSNR), and structural similarity index (SSIM) compared to a popular state of the art denoising method in the presence of strong noises.