 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-reflection in Automated Qualitative Coding: Improving Text Annotation through Secondary LLM Critique
Jan 14, 2026Large language models (LLMs) allow for sophisticated qualitative coding of large datasets, but zero- and few-shot classifiers can produce an intolerable number of errors, even with careful, validated prompting. We present a simple, generalizable two-stage workflow: an LLM applies a human-designed, LLM-adapted codebook; a secondary LLM critic performs self-reflection on each positive label by re-reading the source text alongside the first model's rationale and issuing a final decision. We evaluate this approach on six qualitative codes over 3,000 high-content emails from Apache Software Foundation project evaluation discussions. Our human-derived audit of 360 positive annotations (60 passages by six codes) found that the first-line LLM had a false-positive rate of 8% to 54%, despite F1 scores of 0.74 and 1.00 in testing. Subsequent recoding of all stage-one annotations via a second self-reflection stage improved F1 by 0.04 to 0.25, bringing two especially poor performing codes up to 0.69 and 0.79 from 0.52 and 0.55 respectively. Our manual evaluation identified two recurrent error classes: misinterpretation (violations of code definitions) and meta-discussion (debate about a project evaluation criterion mistaken for its use as a decision justification). Code-specific critic clauses addressing observed failure modes were especially effective with testing and refinement, replicating the codebook-adaption process for LLM interpretation in stage-one. We explain how favoring recall in first-line LLM annotation combined with secondary critique delivers precision-first, compute-light control. With human guidance and validation, self-reflection slots into existing LLM-assisted annotation pipelines to reduce noise and potentially salvage unusable classifiers.
Responsible AI in Open Ecosystems: Reconciling Innovation with Risk Assessment and Disclosure
Sep 27, 2024The rapid scaling of AI has spurred a growing emphasis on ethical considerations in both development and practice. This has led to the formulation of increasingly sophisticated model auditing and reporting requirements, as well as governance frameworks to mitigate potential risks to individuals and society. At this critical juncture, we review the practical challenges of promoting responsible AI and transparency in informal sectors like OSS that support vital infrastructure and see widespread use. We focus on how model performance evaluation may inform or inhibit probing of model limitations, biases, and other risks. Our controlled analysis of 7903 Hugging Face projects found that risk documentation is strongly associated with evaluation practices. Yet, submissions (N=789) from the platform's most popular competitive leaderboard showed less accountability among high performers. Our findings can inform AI providers and legal scholars in designing interventions and policies that preserve open-source innovation while incentivizing ethical uptake.
Machine Translation for Accessible Multi-Language Text Analysis
Jan 20, 2023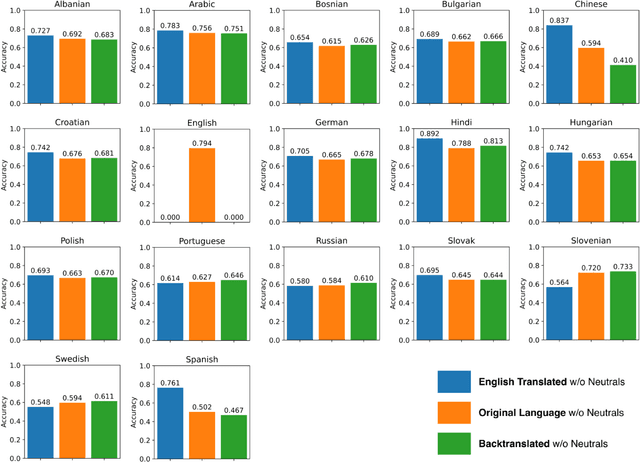
English is the international standard of social research, but scholars are increasingly conscious of their responsibility to meet the need for scholarly insight into communication processes globally. This tension is as true in computational methods as any other area, with revolutionary advances in the tools for English language texts leaving most other languages far behind. In this paper, we aim to leverage those very advances to demonstrate that multi-language analysis is currently accessible to all computational scholars. We show that English-trained measures computed after translation to English have adequate-to-excellent accuracy compared to source-language measures computed on original texts. We show this for three major analytics -- sentiment analysis, topic analysis, and word embeddings -- over 16 languages, including Spanish, Chinese, Hindi, and Arabic. We validate this claim by comparing predictions on original language tweets and their backtranslations: double translations from their source language to English and back to the source language. Overall, our results suggest that Google Translate, a simple and widely accessible tool, is effective in preserving semantic content across languages and methods. Modern machine translation can thus help computational scholars make more inclusive and general claims about human communication.