 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsifying and Down-scaling Networks to Increase Robustness to Distortions
Jun 08, 2020



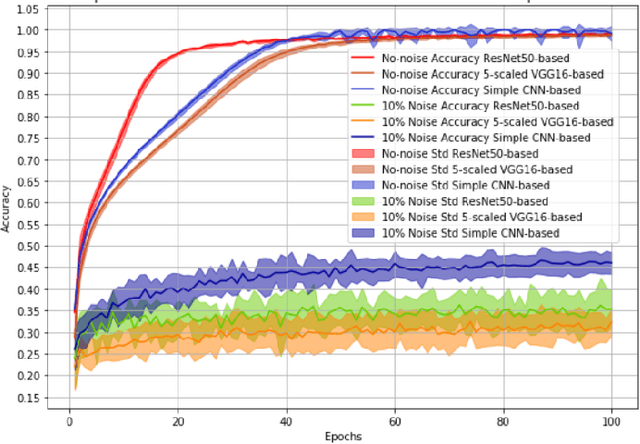
It has been shown that perfectly trained networks exhibit drastic reduction in performance when presented with distorted images. Streaming Network (STNet) is a novel architecture capable of robust classification of the distorted images while been trained on undistorted images. The distortion robustness is enabled by means of sparse input and isolated parallel streams with decoupled weights. Recent results prove STNet is robust to 20 types of noise and distortions. STNet exhibits state-of-the-art performance for classification of low light images, while being of much smaller size when other networks. In this paper, we construct STNets by using scaled versions (number of filters in each layer is reduced by factor of n) of popular networks like VGG16, ResNet50 and MobileNetV2 as parallel streams. These new STNets are tested on several datasets. Our results indicate that more efficient (less FLOPS), new STNets exhibit higher or equal accuracy in comparison with original networks. Considering a diversity of datasets and networks used for tests, we conclude that a new type of STNets is an efficient tool for robust classification of distorted images.
Streaming Networks: Increase Noise Robustness and Filter Diversity via Hard-wired and Input-induced Sparsity
Apr 09, 2020

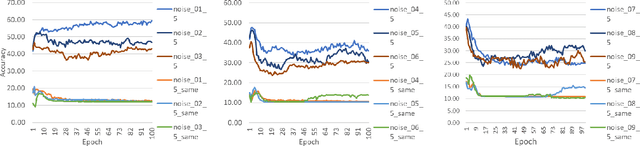
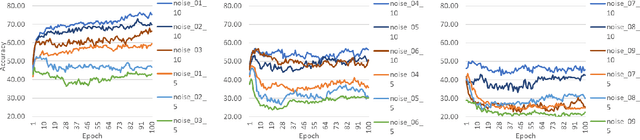
The CNNs have achieved a state-of-the-art performance in many applications. Recent studies illustrate that CNN's recognition accuracy drops drastically if images are noise corrupted. We focus on the problem of robust recognition accuracy of noise-corrupted images. We introduce a novel network architecture called Streaming Networks. Each stream is taking a certain intensity slice of the original image as an input, and stream parameters are trained independently. We use network capacity, hard-wired and input-induced sparsity as the dimensions for experiments. The results indicate that only the presence of both hard-wired and input-induces sparsity enables robust noisy image recognition. Streaming Nets is the only architecture which has both types of sparsity and exhibits higher robustness to noise. Finally, to illustrate increase in filter diversity we illustrate that a distribution of filter weights of the first conv layer gradually approaches uniform distribution as the degree of hard-wired and domain-induced sparsity and capacities increases.
Applications of the Streaming Networks
Mar 27, 2020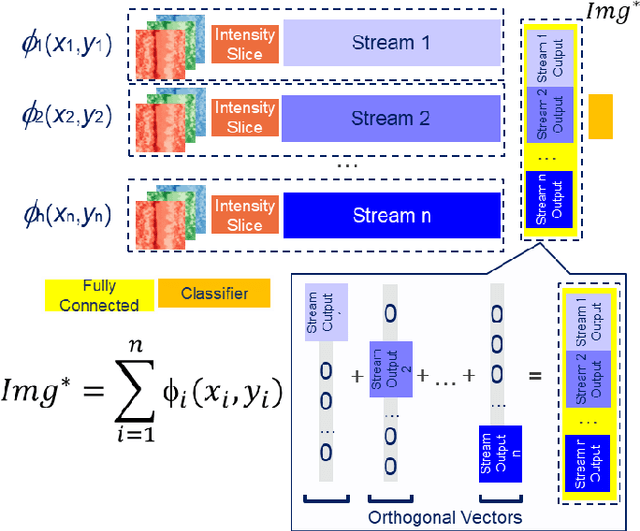
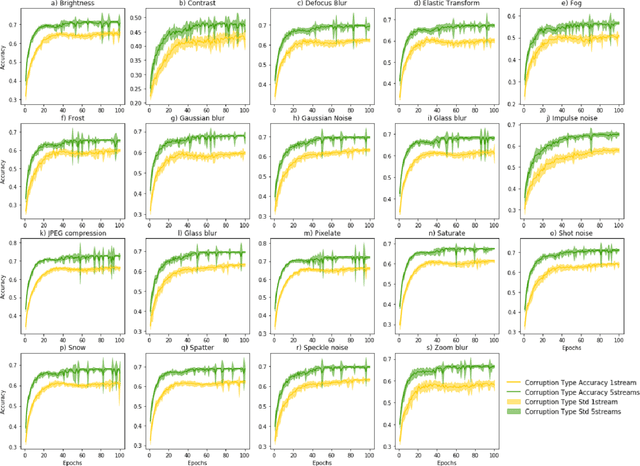
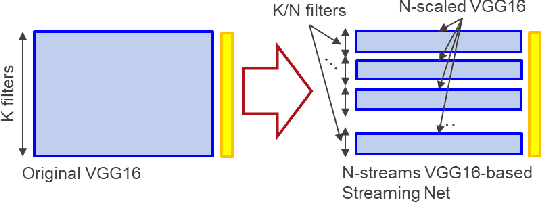
Most recently Streaming Networks (STnets) have been introduced as a mechanism of robust noise-corrupted images classification. STnets is a family of convolutional neural networks, which consists of multiple neural networks (streams), which have different inputs and their outputs are concatenated and fed into a single joint classifier. The original paper has illustrated how STnets can successfully classify images from Cifar10, EuroSat and UCmerced datasets, when images were corrupted with various levels of random zero noise. In this paper, we demonstrate that STnets are capable of high accuracy classification of images corrupted with Gaussian noise, fog, snow, etc. (Cifar10 corrupted dataset) and low light images (subset of Carvana dataset). We also introduce a new type of STnets called Hybrid STnets. Thus, we illustrate that STnets is a universal tool of image classification when original training dataset is corrupted with noise or other transformations, which lead to information loss from original images.
Streaming Networks: Enable A Robust Classification of Noise-Corrupted Images
Oct 23, 2019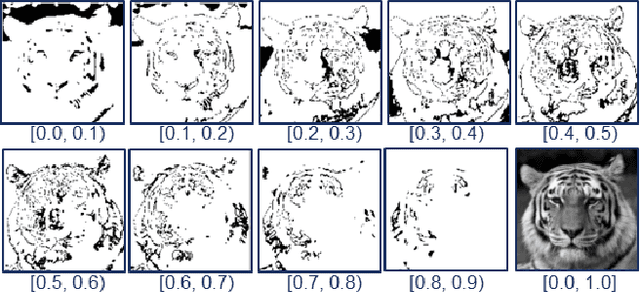
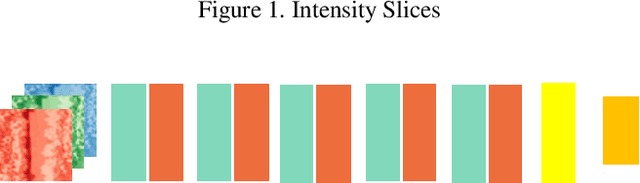
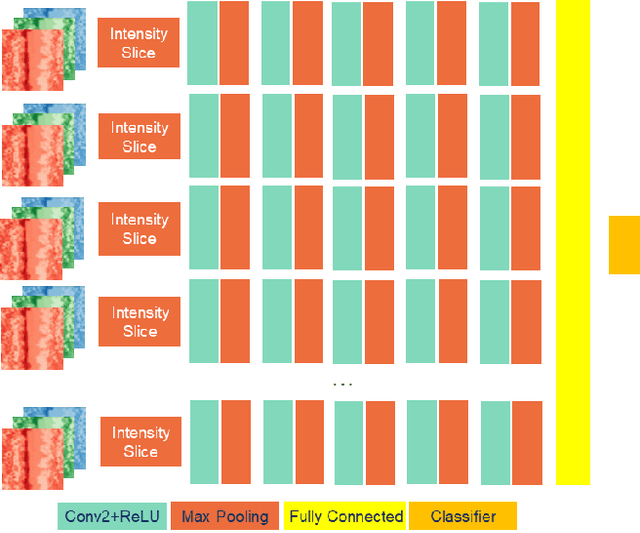
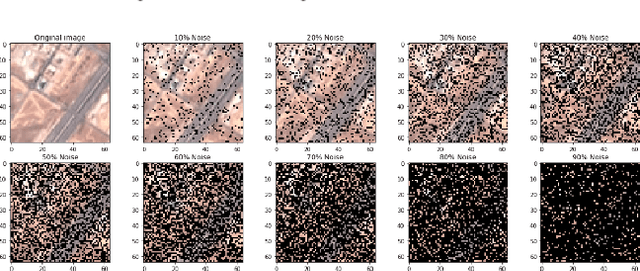
The convolution neural nets (conv nets) have achieved a state-of-the-art performance in many applications of image and video processing. The most recent studies illustrate that the conv nets are fragile in terms of recognition accuracy to various image distortions such as noise, scaling, rotation, etc. In this study we focus on the problem of robust recognition accuracy of random noise distorted images. A common solution to this problem is either to add a lot of noisy images into a training dataset, which can be very costly, or use sophisticated loss function and denoising techniques. We introduce a novel conv net architecture with multiple streams. Each stream is taking a certain intensity slice of the original image as an input, and stream parameters are trained independently. We call this novel network a "Streaming Net". Our results indicate that Streaming Net outperforms 1-stream conv net (employed as a single stream) and 1-stream wide conv net (employs the same number of filters as Streaming Net) in recognition accuracy of noise-corrupted images, while producing the same or higher recognition accuracy of no noise images in almost all of the tests. Thus, we introduce a new simple method to increase robustness of recognition of noisy images without using data generation or sophisticated training techniques.
Unsupervised Neural Architecture for Saliency Detection: Extended Version
Apr 10, 2015



We propose a novel neural network architecture for visual saliency detections, which utilizes neurophysiologically plausible mechanisms for extraction of salient regions. The model has been significantly inspired by recent findings from neurophysiology and aimed to simulate the bottom-up processes of human selective attention. Two types of features were analyzed: color and direction of maximum variance. The mechanism we employ for processing those features is PCA, implemented by means of normalized Hebbian learning and the waves of spikes. To evaluate performance of our model we have conducted psychological experiment. Comparison of simulation results with those of experiment indicates good performance of our model.
Modeling multistage decision processes with Reflexive Game Theory
Mar 11, 2012



This paper introduces application of Reflexive Game Theory to the matter of multistage decision making processes. The idea behind is that each decision making session has certain parameters like "when the session is taking place", "who are the group members to make decision", "how group members influence on each other", etc. This study illustrates the consecutive or sequential decision making process, which consist of two stages. During the stage 1 decisions about the parameters of the ultimate decision making are made. Then stage 2 is implementation of Ultimate decision making itself. Since during stage 1 there can be multiple decision sessions. In such a case it takes more than two sessions to make ultimate (final) decision. Therefore the overall process of ultimate decision making becomes multistage decision making process consisting of consecutive decision making sessions.
The Inverse Task of the Reflexive Game Theory: Theoretical Matters, Practical Applications and Relationship with Other Issues
Nov 15, 2010



The Reflexive Game Theory (RGT) has been recently proposed by Vladimir Lefebvre to model behavior of individuals in groups. The goal of this study is to introduce the Inverse task. We consider methods of solution together with practical applications. We present a brief overview of the RGT for easy understanding of the problem. We also develop the schematic representation of the RGT inference algorithms to create the basis for soft- and hardware solutions of the RGT tasks. We propose a unified hierarchy of schemas to represent humans and robots. This hierarchy is considered as a unified framework to solve the entire spectrum of the RGT tasks. We conclude by illustrating how this framework can be applied for modeling of mixed groups of humans and robots. All together this provides the exhaustive solution of the Inverse task and clearly illustrates its role and relationships with other issues considered in the RGT.