 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradMix: Gradient-based Selective Mixup for Robust Data Augmentation in Class-Incremental Learning
May 13, 2025In the context of continual learning, acquiring new knowledge while maintaining previous knowledge presents a significant challenge. Existing methods often use experience replay techniques that store a small portion of previous task data for training. In experience replay approaches, data augmentation has emerged as a promising strategy to further improve the model performance by mixing limited previous task data with sufficient current task data. However, we theoretically and empirically analyze that training with mixed samples from random sample pairs may harm the knowledge of previous tasks and cause greater catastrophic forgetting. We then propose GradMix, a robust data augmentation method specifically designed for mitigating catastrophic forgetting in class-incremental learning. GradMix performs gradient-based selective mixup using a class-based criterion that mixes only samples from helpful class pairs and not from detrimental class pairs for reducing catastrophic forgetting. Our experiments on various real datasets show that GradMix outperforms data augmentation baselines in accuracy by minimizing the forgetting of previous knowledge.
T-CIL: Temperature Scaling using Adversarial Perturbation for Calibration in Class-Incremental Learning
Mar 28, 2025We study model confidence calibration in class-incremental learning, where models learn from sequential tasks with different class sets. While existing works primarily focus on accuracy, maintaining calibrated confidence has been largely overlooked. Unfortunately, most post-hoc calibration techniques are not designed to work with the limited memories of old-task data typical in class-incremental learning, as retaining a sufficient validation set would be impractical. Thus, we propose T-CIL, a novel temperature scaling approach for class-incremental learning without a validation set for old tasks, that leverages adversarially perturbed exemplars from memory. Directly using exemplars is inadequate for temperature optimization, since they are already used for training. The key idea of T-CIL is to perturb exemplars more strongly for old tasks than for the new task by adjusting the perturbation direction based on feature distance, with the single magnitude determined using the new-task validation set. This strategy makes the perturbation magnitude computed from the new task also applicable to old tasks, leveraging the tendency that the accuracy of old tasks is lower than that of the new task. We empirically show that T-CIL significantly outperforms various baselines in terms of calibration on real datasets and can be integrated with existing class-incremental learning techniques with minimal impact on accuracy.
RC-Mixup: A Data Augmentation Strategy against Noisy Data for Regression Tasks
May 28, 2024



We study the problem of robust data augmentation for regression tasks in the presence of noisy data. Data augmentation is essential for generalizing deep learning models, but most of the techniques like the popular Mixup are primarily designed for classification tasks on image data. Recently, there are also Mixup techniques that are specialized to regression tasks like C-Mixup. In comparison to Mixup, which takes linear interpolations of pairs of samples, C-Mixup is more selective in which samples to mix based on their label distances for better regression performance. However, C-Mixup does not distinguish noisy versus clean samples, which can be problematic when mixing and lead to suboptimal model performance. At the same time, robust training has been heavily studied where the goal is to train accurate models against noisy data through multiple rounds of model training. We thus propose our data augmentation strategy RC-Mixup, which tightly integrates C-Mixup with multi-round robust training methods for a synergistic effect. In particular, C-Mixup improves robust training in identifying clean data, while robust training provides cleaner data to C-Mixup for it to perform better. A key advantage of RC-Mixup is that it is data-centric where the robust model training algorithm itself does not need to be modified, but can simply benefit from data mixing. We show in our experiments that RC-Mixup significantly outperforms C-Mixup and robust training baselines on noisy data benchmarks and can be integrated with various robust training methods.
Quilt: Robust Data Segment Selection against Concept Drifts
Dec 15, 2023Continuous machine learning pipelines are common in industrial settings where models are periodically trained on data streams. Unfortunately, concept drifts may occur in data streams where the joint distribution of the data X and label y, P(X, y), changes over time and possibly degrade model accuracy. Existing concept drift adaptation approaches mostly focus on updating the model to the new data possibly using ensemble techniques of previous models and tend to discard the drifted historical data. However, we contend that explicitly utilizing the drifted data together leads to much better model accuracy and propose Quilt, a data-centric framework for identifying and selecting data segments that maximize model accuracy. To address the potential downside of efficiency, Quilt extends existing data subset selection techniques, which can be used to reduce the training data without compromising model accuracy. These techniques cannot be used as is because they only assume virtual drifts where the posterior probabilities P(y|X) are assumed not to change. In contrast, a key challenge in our setup is to also discard undesirable data segments with concept drifts. Quilt thus discards drifted data segments and selects data segment subsets holistically for accurate and efficient model training. The two operations use gradient-based scores, which have little computation overhead. In our experiments, we show that Quilt outperforms state-of-the-art drift adaptation and data selection baselines on synthetic and real datasets.
MixRL: Data Mixing Augmentation for Regression using Reinforcement Learning
Jun 07, 2021
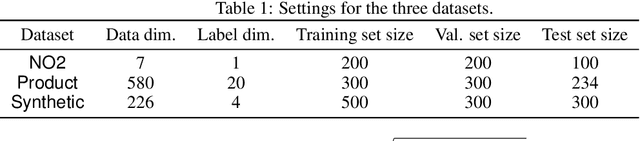
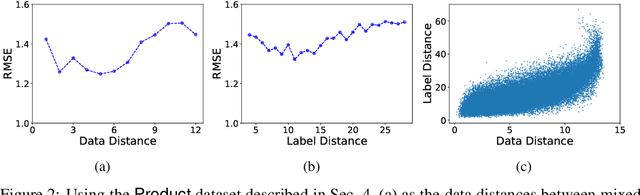
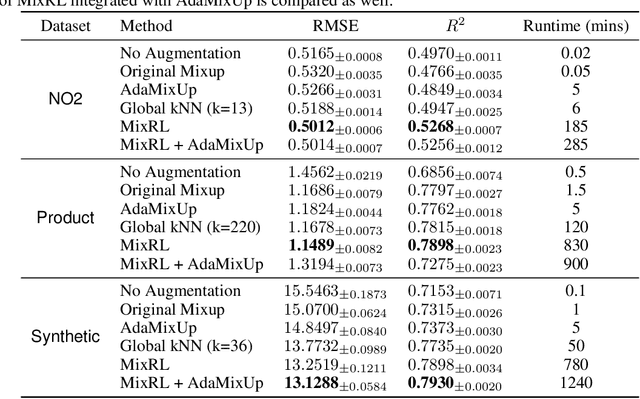
Data augmentation is becoming essential for improving regression accuracy in critical applications including manufacturing and finance. Existing techniques for data augmentation largely focus on classification tasks and do not readily apply to regression tasks. In particular, the recent Mixup techniques for classification rely on the key assumption that linearity holds among training examples, which is reasonable if the label space is discrete, but has limitations when the label space is continuous as in regression. We show that mixing examples that either have a large data or label distance may have an increasingly-negative effect on model performance. Hence, we use the stricter assumption that linearity only holds within certain data or label distances for regression where the degree may vary by each example. We then propose MixRL, a data augmentation meta learning framework for regression that learns for each example how many nearest neighbors it should be mixed with for the best model performance using a small validation set. MixRL achieves these objectives using Monte Carlo policy gradient reinforcement learning. Our experiments conducted both on synthetic and real datasets show that MixRL significantly outperforms state-of-the-art data augmentation baselines. MixRL can also be integrated with other classification Mixup techniques for better results.