 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representation for Multitask learning through Self Supervised Auxiliary learning
Sep 25, 2024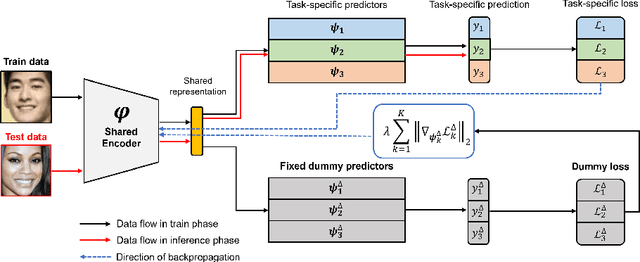
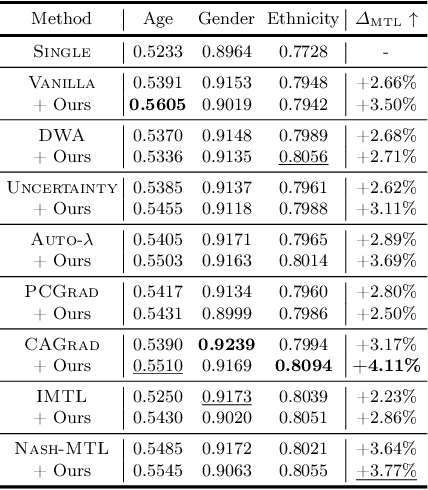
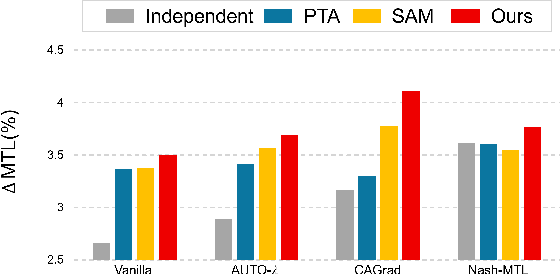
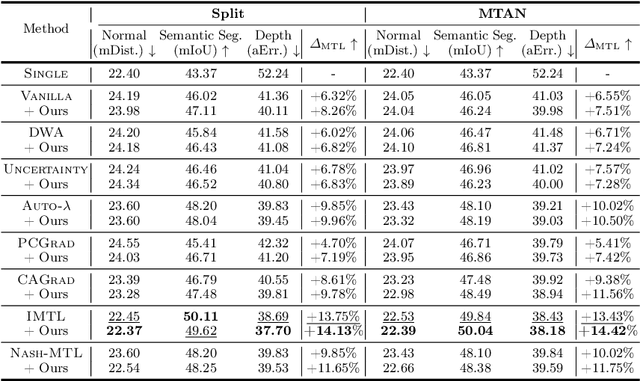
Multi-task learning is a popular machine learning approach that enables simultaneous learning of multiple related tasks, improving algorithmic efficiency and effectiveness. In the hard parameter sharing approach, an encoder shared through multiple tasks generates data representations passed to task-specific predictors. Therefore, it is crucial to have a shared encoder that provides decent representations for every and each task. However, despite recent advances in multi-task learning, the question of how to improve the quality of representations generated by the shared encoder remains open. To address this gap, we propose a novel approach called Dummy Gradient norm Regularization that aims to improve the universality of the representations generated by the shared encoder. Specifically, the method decreases the norm of the gradient of the loss function with repect to dummy task-specific predictors to improve the universality of the shared encoder's representations. Through experiments on multiple multi-task learning benchmark datasets, we demonstrate that DGR effectively improves the quality of the shared representations, leading to better multi-task prediction performances. Applied to various classifiers, the shared representations generated by DGR also show superior performance compared to existing multi-task learning methods. Moreover, our approach takes advantage of computational efficiency due to its simplicity. The simplicity also allows us to seamlessly integrate DGR with the existing multi-task learning algorithms.