 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Variational Approximate Posterior for the Deep Wishart Process
May 23, 2023

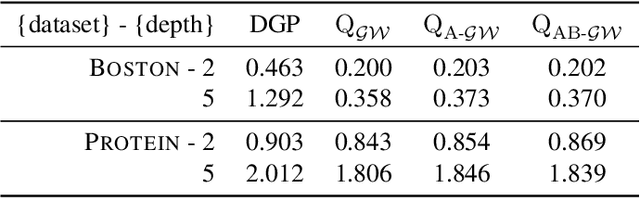

Deep kernel processes are a recently introduced class of deep Bayesian models that have the flexibility of neural networks, but work entirely with Gram matrices. They operate by alternately sampling a Gram matrix from a distribution over positive semi-definite matrices, and applying a deterministic transformation. When the distribution is chosen to be Wishart, the model is called a deep Wishart process (DWP). This particular model is of interest because its prior is equivalent to a deep Gaussian process (DGP) prior, but at the same time it is invariant to rotational symmetries, leading to a simpler posterior distribution. Practical inference in the DWP was made possible in recent work ("A variational approximate posterior for the deep Wishart process" Ober and Aitchison 2021a) where the authors used a generalisation of the Bartlett decomposition of the Wishart distribution as the variational approximate posterior. However, predictive performance in that paper was less impressive than one might expect, with the DWP only beating a DGP on a few of the UCI datasets used for comparison. In this paper, we show that further generalising their distribution to allow linear combinations of rows and columns in the Bartlett decomposition results in better predictive performance, while incurring negligible additional computation cost.