Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Pooling Methods for Video Classification
Oct 01, 2018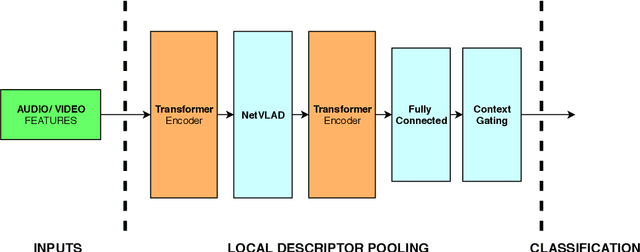
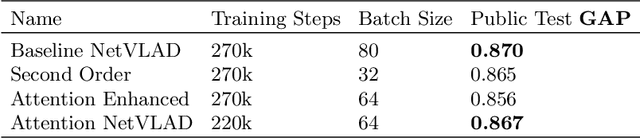
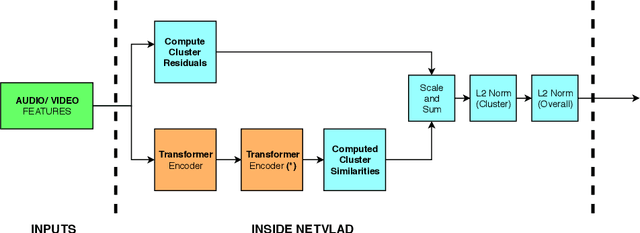
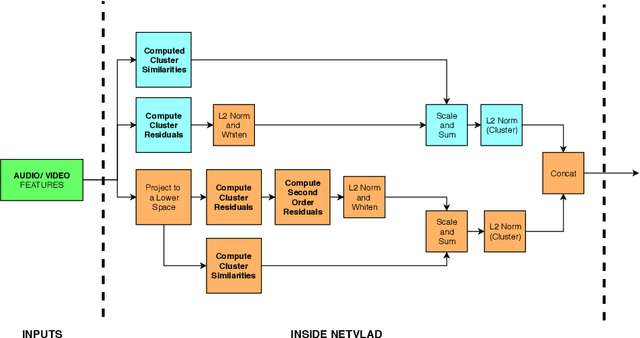
We introduce modifications to state-of-the-art approaches to aggregating local video descriptors by using attention mechanisms and function approximations. Rather than using ensembles of existing architectures, we provide an insight on creating new architectures. We demonstrate our solutions in the "The 2nd YouTube-8M Video Understanding Challenge", by using frame-level video and audio descriptors. We obtain testing accuracy similar to the state of the art, while meeting budget constraints, and touch upon strategies to improve the state of the art. Model implementations are available in https://github.com/pomonam/LearnablePoolingMethods.
* Presented at Youtube 8M ECCV18 Workshop
Via