 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbout Explicit Variance Minimization: Training Neural Networks for Medical Imaging With Limited Data Annotations
Jun 03, 2021
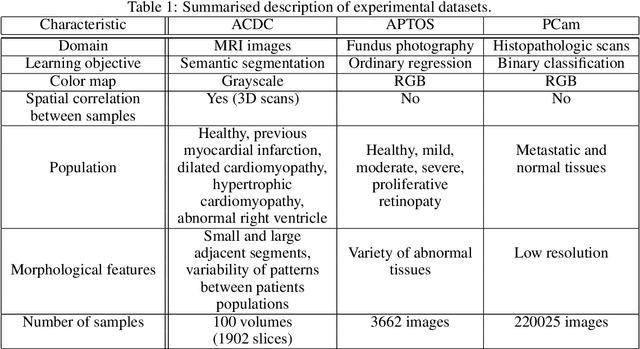
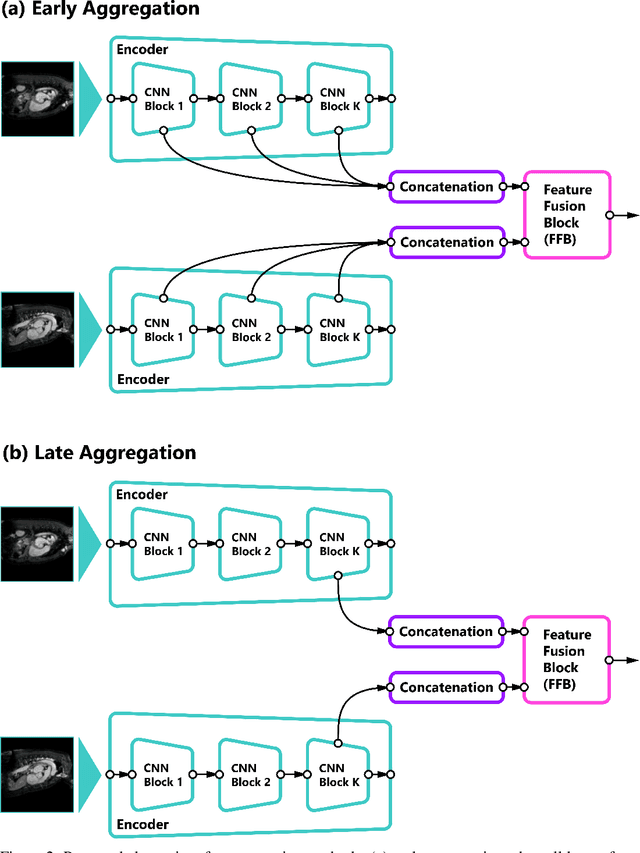
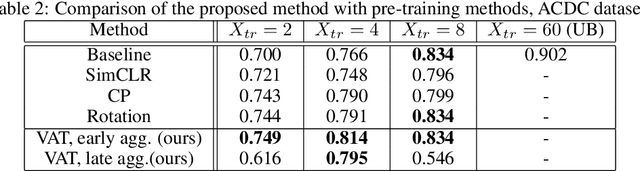
Self-supervised learning methods for computer vision have demonstrated the effectiveness of pre-training feature representations, resulting in well-generalizing Deep Neural Networks, even if the annotated data are limited. However, representation learning techniques require a significant amount of time for model training, with most of it time spent on precise hyper-parameter optimization and selection of augmentation techniques. We hypothesized that if the annotated dataset has enough morphological diversity to capture the general population's as is common in medical imaging, for example, due to conserved similarities of tissue mythologies, the variance error of the trained model is the prevalent component of the Bias-Variance Trade-off. We propose the Variance Aware Training (VAT) method that exploits this property by introducing the variance error into the model loss function, i.e., enabling minimizing the variance explicitly. Additionally, we provide the theoretical formulation and proof of the proposed method to aid in interpreting the approach. Our method requires selecting only one hyper-parameter and was able to match or improve the state-of-the-art performance of self-supervised methods while achieving an order of magnitude reduction in the GPU training time. We validated VAT on three medical imaging datasets from diverse domains and various learning objectives. These included a Magnetic Resonance Imaging (MRI) dataset for the heart semantic segmentation (MICCAI 2017 ACDC challenge), fundus photography dataset for ordinary regression of diabetic retinopathy progression (Kaggle 2019 APTOS Blindness Detection challenge), and classification of histopathologic scans of lymph node sections (PatchCamelyon dataset).