 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Timbre Synthesis using Variational Autoencoders Regularized on Timbre Descriptors
Jul 18, 2023Controllable timbre synthesis has been a subject of research for several decades, and deep neural networks have been the most successful in this area. Deep generative models such as Variational Autoencoders (VAEs) have the ability to generate a high-level representation of audio while providing a structured latent space. Despite their advantages, the interpretability of these latent spaces in terms of human perception is often limited. To address this limitation and enhance the control over timbre generation, we propose a regularized VAE-based latent space that incorporates timbre descriptors. Moreover, we suggest a more concise representation of sound by utilizing its harmonic content, in order to minimize the dimensionality of the latent space.
An investigation of the reconstruction capacity of stacked convolutional autoencoders for log-mel-spectrograms
Jan 18, 2023



In audio processing applications, the generation of expressive sounds based on high-level representations demonstrates a high demand. These representations can be used to manipulate the timbre and influence the synthesis of creative instrumental notes. Modern algorithms, such as neural networks, have inspired the development of expressive synthesizers based on musical instrument timbre compression. Unsupervised deep learning methods can achieve audio compression by training the network to learn a mapping from waveforms or spectrograms to low-dimensional representations. This study investigates the use of stacked convolutional autoencoders for the compression of time-frequency audio representations for a variety of instruments for a single pitch. Further exploration of hyper-parameters and regularization techniques is demonstrated to enhance the performance of the initial design. In an unsupervised manner, the network is able to reconstruct a monophonic and harmonic sound based on latent representations. In addition, we introduce an evaluation metric to measure the similarity between the original and reconstructed samples. Evaluating a deep generative model for the synthesis of sound is a challenging task. Our approach is based on the accuracy of the generated frequencies as it presents a significant metric for the perception of harmonic sounds. This work is expected to accelerate future experiments on audio compression using neural autoencoders.
Audio representations for deep learning in sound synthesis: A review
Jan 07, 2022
The rise of deep learning algorithms has led many researchers to withdraw from using classic signal processing methods for sound generation. Deep learning models have achieved expressive voice synthesis, realistic sound textures, and musical notes from virtual instruments. However, the most suitable deep learning architecture is still under investigation. The choice of architecture is tightly coupled to the audio representations. A sound's original waveform can be too dense and rich for deep learning models to deal with efficiently - and complexity increases training time and computational cost. Also, it does not represent sound in the manner in which it is perceived. Therefore, in many cases, the raw audio has been transformed into a compressed and more meaningful form using upsampling, feature-extraction, or even by adopting a higher level illustration of the waveform. Furthermore, conditional on the form chosen, additional conditioning representations, different model architectures, and numerous metrics for evaluating the reconstructed sound have been investigated. This paper provides an overview of audio representations applied to sound synthesis using deep learning. Additionally, it presents the most significant methods for developing and evaluating a sound synthesis architecture using deep learning models, always depending on the audio representation.
A sinusoidal signal reconstruction method for the inversion of the mel-spectrogram
Jan 07, 2022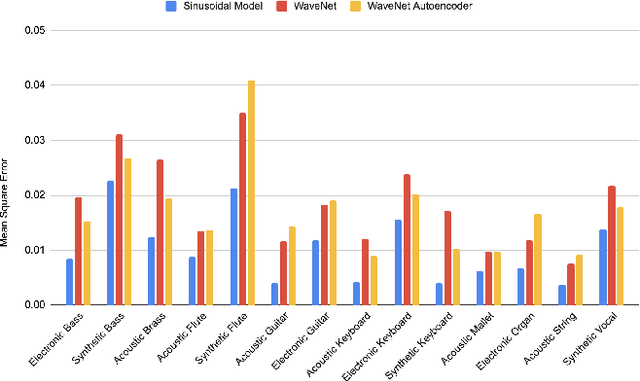
The synthesis of sound via deep learning methods has recently received much attention. Some problems for deep learning approaches to sound synthesis relate to the amount of data needed to specify an audio signal and the necessity of preserving both the long and short time coherence of the synthesised signal. Visual time-frequency representations such as the log-mel-spectrogram have gained in popularity. The log-mel-spectrogram is a perceptually informed representation of audio that greatly compresses the amount of information required for the description of the sound. However, because of this compression, this representation is not directly invertible. Both signal processing and machine learning techniques have previously been applied to the inversion of the log-mel-spectrogram but they both caused audible distortions in the synthesized sounds due to issues of temporal and spectral coherence. In this paper, we outline the application of a sinusoidal model to the inversion of the log-mel-spectrogram for pitched musical instrument sounds outperforming state-of-the-art deep learning methods. The approach could be later used as a general decoding step from spectral to time intervals in neural applications.