 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA sinusoidal signal reconstruction method for the inversion of the mel-spectrogram
Paper and Code
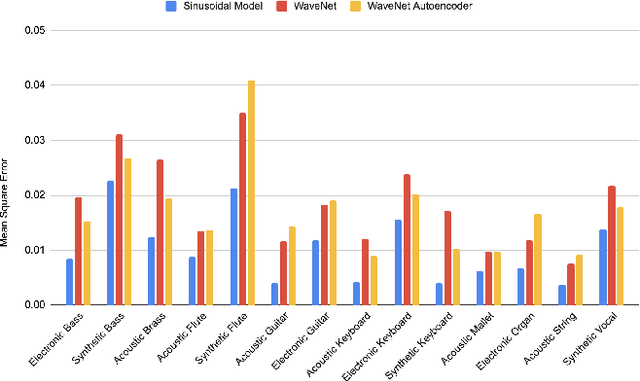
The synthesis of sound via deep learning methods has recently received much attention. Some problems for deep learning approaches to sound synthesis relate to the amount of data needed to specify an audio signal and the necessity of preserving both the long and short time coherence of the synthesised signal. Visual time-frequency representations such as the log-mel-spectrogram have gained in popularity. The log-mel-spectrogram is a perceptually informed representation of audio that greatly compresses the amount of information required for the description of the sound. However, because of this compression, this representation is not directly invertible. Both signal processing and machine learning techniques have previously been applied to the inversion of the log-mel-spectrogram but they both caused audible distortions in the synthesized sounds due to issues of temporal and spectral coherence. In this paper, we outline the application of a sinusoidal model to the inversion of the log-mel-spectrogram for pitched musical instrument sounds outperforming state-of-the-art deep learning methods. The approach could be later used as a general decoding step from spectral to time intervals in neural applications.