 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA logical word embedding for learning grammar
Apr 28, 2023



We introduce the logical grammar emdebbing (LGE), a model inspired by pregroup grammars and categorial grammars to enable unsupervised inference of lexical categories and syntactic rules from a corpus of text. LGE produces comprehensible output summarizing its inferences, has a completely transparent process for producing novel sentences, and can learn from as few as a hundred sentences.
A transparent approach to data representation
Apr 27, 2023



We use a binary attribute representation (BAR) model to describe a data set of Netflix viewers' ratings of movies. We classify the viewers with discrete bits rather than continuous parameters, which makes the representation compact and transparent. The attributes are easy to interpret, and we need far fewer attributes than similar methods do to achieve the same level of error. We also take advantage of the nonuniform distribution of ratings among the movies in the data set to train on a small selection of movies without compromising performance on the rest of the movies.
Solving a directed percolation inverse problem with a divide-and-concur algorithm
Feb 11, 2022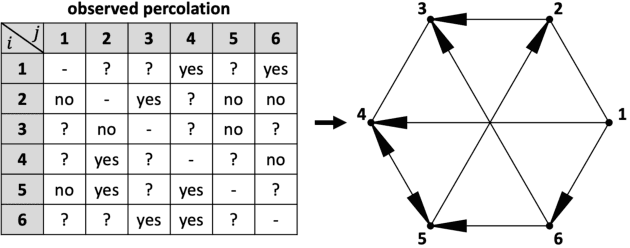
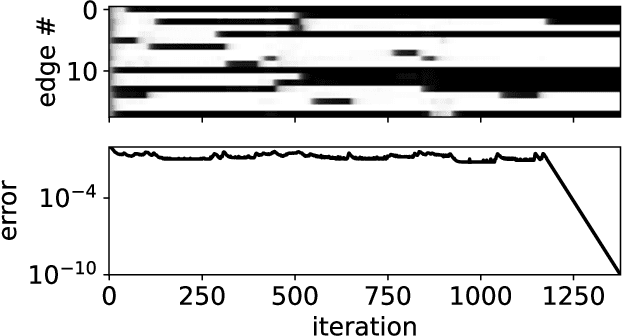
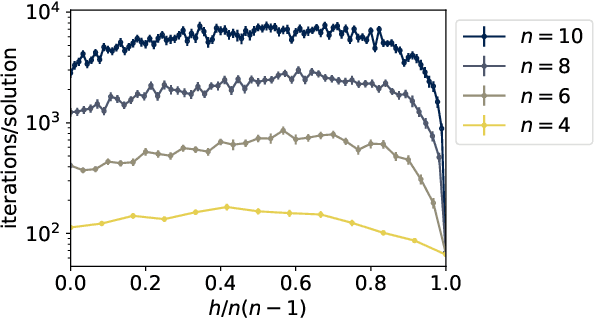
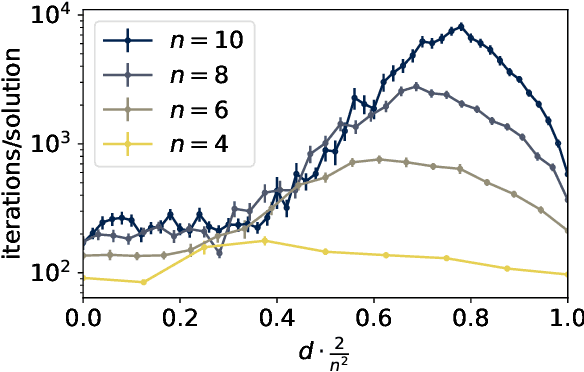
We present a directed percolation inverse problem for diode networks: Given information about which pairs of nodes allow current to percolate from one to the other, can one find a configuration of diodes consistent with the observed currents? We implement a divide-and-concur iterative projection method for solving the problem and demonstrate the supremacy of our method over an exhaustive approach for nontrivial instances of the problem. We find that the problem is most difficult when some but not all of the percolation data are hidden, and that the most difficult networks to reconstruct generally are those for which the currents are most sensitive to the addition or removal of a single diode.
Learning grammar with a divide-and-concur neural network
Jan 21, 2022



We implement a divide-and-concur iterative projection approach to context-free grammar inference. Unlike most state-of-the-art models of natural language processing, our method requires a relatively small number of discrete parameters, making the inferred grammar directly interpretable -- one can read off from a solution how to construct grammatically valid sentences. Another advantage of our approach is the ability to infer meaningful grammatical rules from just a few sentences, compared to the hundreds of gigabytes of training data many other models employ. We demonstrate several ways of applying our approach: classifying words and inferring a grammar from scratch, taking an existing grammar and refining its categories and rules, and taking an existing grammar and expanding its lexicon as it encounters new words in new data.
Avoiding Traps in Nonconvex Problems
Jun 09, 2021


Iterative projection methods may become trapped at non-solutions when the constraint sets are nonconvex. Two kinds of parameters are available to help avoid this behavior and this study gives examples of both. The first kind of parameter, called a hyperparameter, includes any kind of parameter that appears in the definition of the iteration rule itself. The second kind comprises metric parameters in the definition of the constraint sets, a feature that arises when the problem to be solved has two or more kinds of variables. Through examples we show the importance of properly tuning both kinds of parameters and offer heuristic interpretations of the observed behavior.