 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Embedded Diachronic Sense Change Model with a Case Study from Ancient Greek
Nov 01, 2023Word meanings change over time, and word senses evolve, emerge or die out in the process. For ancient languages, where the corpora are often small, sparse and noisy, modelling such changes accurately proves challenging, and quantifying uncertainty in sense-change estimates consequently becomes important. GASC and DiSC are existing generative models that have been used to analyse sense change for target words from an ancient Greek text corpus, using unsupervised learning without the help of any pre-training. These models represent the senses of a given target word such as "kosmos" (meaning decoration, order or world) as distributions over context words, and sense prevalence as a distribution over senses. The models are fitted using MCMC methods to measure temporal changes in these representations. In this paper, we introduce EDiSC, an embedded version of DiSC, which combines word embeddings with DiSC to provide superior model performance. We show empirically that EDiSC offers improved predictive accuracy, ground-truth recovery and uncertainty quantification, as well as better sampling efficiency and scalability properties with MCMC methods. We also discuss the challenges of fitting these models.
Measuring diachronic sense change: new models and Monte Carlo methods for Bayesian inference
Apr 14, 2021
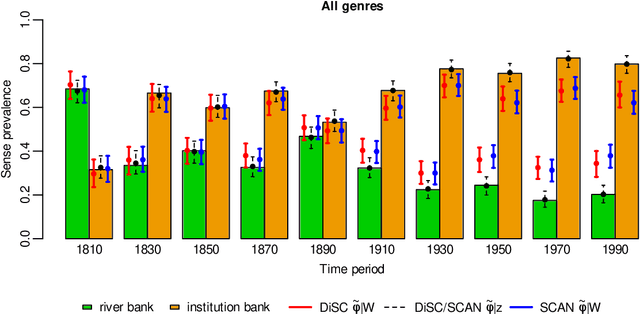

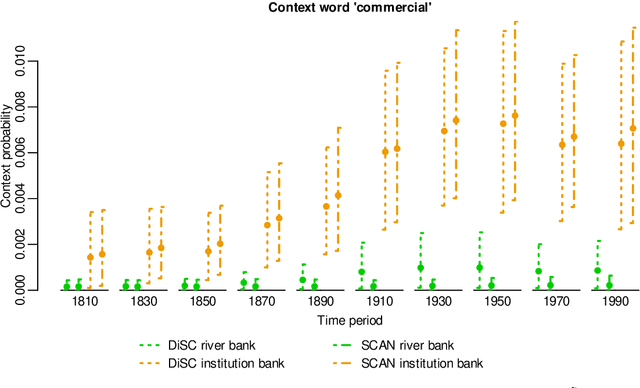
In a bag-of-words model, the senses of a word with multiple meanings, e.g. "bank" (used either in a river-bank or an institution sense), are represented as probability distributions over context words, and sense prevalence is represented as a probability distribution over senses. Both of these may change with time. Modelling and measuring this kind of sense change is challenging due to the typically high-dimensional parameter space and sparse datasets. A recently published corpus of ancient Greek texts contains expert-annotated sense labels for selected target words. Automatic sense-annotation for the word "kosmos" (meaning decoration, order or world) has been used as a test case in recent work with related generative models and Monte Carlo methods. We adapt an existing generative sense change model to develop a simpler model for the main effects of sense and time, and give MCMC methods for Bayesian inference on all these models that are more efficient than existing methods. We carry out automatic sense-annotation of snippets containing "kosmos" using our model, and measure the time-evolution of its three senses and their prevalence. As far as we are aware, ours is the first analysis of this data, within the class of generative models we consider, that quantifies uncertainty and returns credible sets for evolving sense prevalence in good agreement with those given by expert annotation.