 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs to Enable Natural Language Search on Go-to-market Platforms
Nov 07, 2024



Enterprise searches require users to have complex knowledge of queries, configurations, and metadata, rendering it difficult for them to access information as needed. Most go-to-market (GTM) platforms utilize advanced search, an interface that enables users to filter queries by various fields using categories or keywords, which, historically, however, has proven to be exceedingly cumbersome, as users are faced with seemingly hundreds of options, fields, and buttons. Consequently, querying with natural language has long been ideal, a notion further empowered by Large Language Models (LLMs). In this paper, we implement and evaluate a solution for the Zoominfo product for sellers, which prompts the LLM with natural language, producing search fields through entity extraction that are then converted into a search query. The intermediary search fields offer numerous advantages for each query, including the elimination of syntax errors, simpler ground truths, and an intuitive format for the LLM to interpret. We paired this pipeline with many advanced prompt engineering strategies, featuring an intricate system message, few-shot prompting, chain-of-thought (CoT) reasoning, and execution refinement. Furthermore, we manually created the ground truth for 500+ natural language queries, enabling the supervised fine-tuning of Llama-3-8B-Instruct and the introduction of sophisticated numerical metrics. Comprehensive experiments with closed, open source, and fine-tuned LLM models were conducted through exact, Jaccard, cosine, and semantic similarity on individual search entities to demonstrate the efficacy of our approach. Overall, the most accurate closed model had an average accuracy of 97% per query, with only one field performing under 90%, with comparable results observed from the fine-tuned models.
Topic subject creation using unsupervised learning for topic modeling
Dec 18, 2019


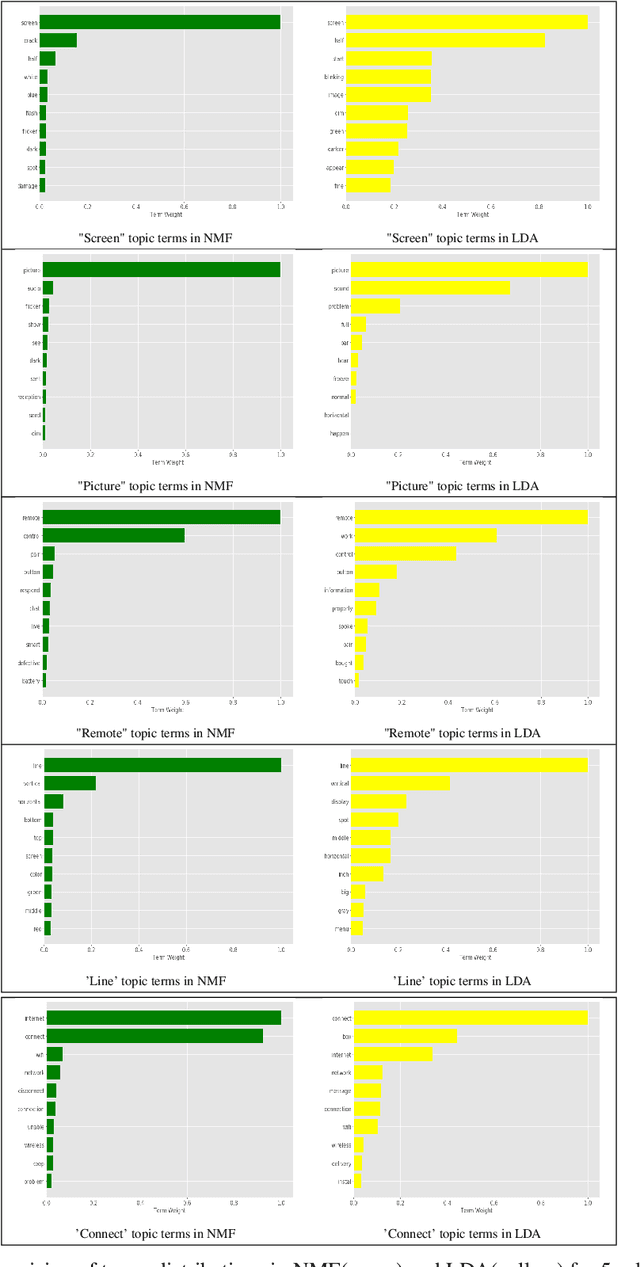
We describe the use of Non-Negative Matrix Factorization (NMF) and Latent Dirichlet Allocation (LDA) algorithms to perform topic mining and labelling applied to retail customer communications in attempt to characterize the subject of customers inquiries. In this paper we compare both algorithms in the topic mining performance and propose methods to assign topic subject labels in an automated way.
Real-time Top-K Predictive Query Processing over Event Streams
Aug 26, 2015



This paper addresses the problem of predicting the k events that are most likely to occur next, over historical real-time event streams. Existing approaches to causal prediction queries have a number of limitations. First, they exhaustively search over an acyclic causal network to find the most likely k effect events; however, data from real event streams frequently reflect cyclic causality. Second, they contain conservative assumptions intended to exclude all possible non-causal links in the causal network; it leads to the omission of many less-frequent but important causal links. We overcome these limitations by proposing a novel event precedence model and a run-time causal inference mechanism. The event precedence model constructs a first order absorbing Markov chain incrementally over event streams, where an edge between two events signifies a temporal precedence relationship between them, which is a necessary condition for causality. Then, the run-time causal inference mechanism learns causal relationships dynamically during query processing. This is done by removing some of the temporal precedence relationships that do not exhibit causality in the presence of other events in the event precedence model. This paper presents two query processing algorithms -- one performs exhaustive search on the model and the other performs a more efficient reduced search with early termination. Experiments using two real datasets (cascading blackouts in power systems and web page views) verify the effectiveness of the probabilistic top-k prediction queries and the efficiency of the algorithms. Specifically, the reduced search algorithm reduced runtime, relative to exhaustive search, by 25-80% (depending on the application) with only a small reduction in accuracy.