 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLife of PII -- A PII Obfuscation Transformer
May 17, 2023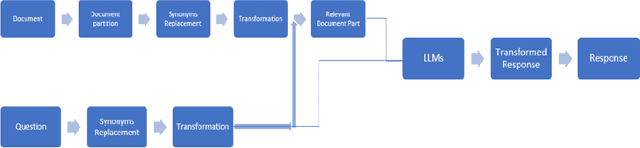


Protecting sensitive information is crucial in today's world of Large Language Models (LLMs) and data-driven services. One common method used to preserve privacy is by using data perturbation techniques to reduce overreaching utility of (sensitive) Personal Identifiable Information (PII) data while maintaining its statistical and semantic properties. Data perturbation methods often result in significant information loss, making them impractical for use. In this paper, we propose 'Life of PII', a novel Obfuscation Transformer framework for transforming PII into faux-PII while preserving the original information, intent, and context as much as possible. Our approach includes an API to interface with the given document, a configuration-based obfuscator, and a model based on the Transformer architecture, which has shown high context preservation and performance in natural language processing tasks and LLMs. Our Transformer-based approach learns mapping between the original PII and its transformed faux-PII representation, which we call "obfuscated" data. Our experiments demonstrate that our method, called Life of PII, outperforms traditional data perturbation techniques in terms of both utility preservation and privacy protection. We show that our approach can effectively reduce utility loss while preserving the original information, offering greater flexibility in the trade-off between privacy protection and data utility. Our work provides a solution for protecting PII in various real-world applications.
TableZa -- A classical Computer Vision approach to Tabular Extraction
May 19, 2021

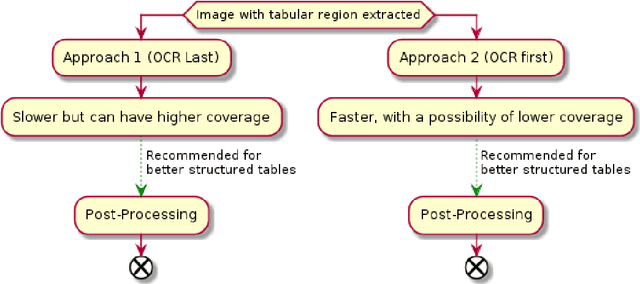

Computer aided Tabular Data Extraction has always been a very challenging and error prone task because it demands both Spectral and Spatial Sanity of data. In this paper we discuss an approach for Tabular Data Extraction in the realm of document comprehension. Given the different kinds of the Tabular formats that are often found across various documents, we discuss a novel approach using Computer Vision for extraction of tabular data from images or vector pdf(s) converted to image(s).
Classification of descriptions and summary using multiple passes of statistical and natural language toolkits
Sep 10, 2020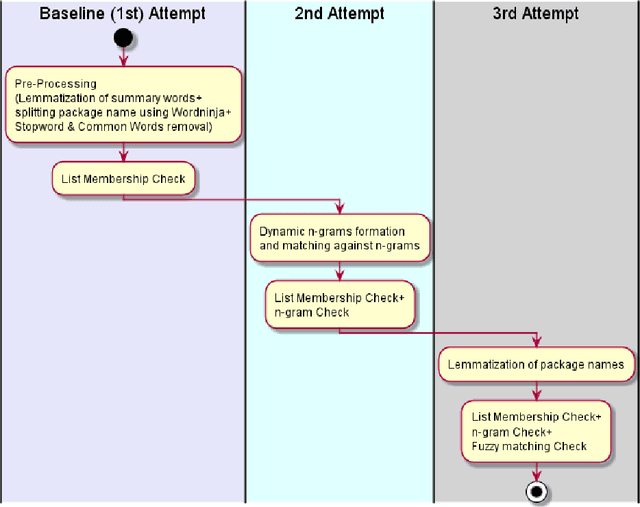



This document describes a possible approach that can be used to check the relevance of a summary / definition of an entity with respect to its name. This classifier focuses on the relevancy of an entity's name to its summary / definition, in other words, it is a name relevance check. The percentage score obtained from this approach can be used either on its own or used to supplement scores obtained from other metrics to arrive upon a final classification; at the end of the document, potential improvements have also been outlined. The dataset that this document focuses on achieving an objective score is a list of package names and their respective summaries (sourced from pypi.org).