Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableZa -- A classical Computer Vision approach to Tabular Extraction
Paper and Code
May 19, 2021

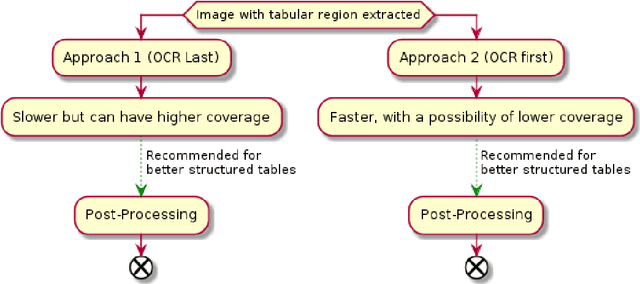

Computer aided Tabular Data Extraction has always been a very challenging and error prone task because it demands both Spectral and Spatial Sanity of data. In this paper we discuss an approach for Tabular Data Extraction in the realm of document comprehension. Given the different kinds of the Tabular formats that are often found across various documents, we discuss a novel approach using Computer Vision for extraction of tabular data from images or vector pdf(s) converted to image(s).
* 14 pages, 16 figures, 1 table
View paper on