 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse-Transpilation: Reverse-Engineering Quantum Compiler Optimization Passes from Circuit Snapshots
Apr 27, 2025Circuit compilation, a crucial process for adapting quantum algorithms to hardware constraints, often operates as a ``black box,'' with limited visibility into the optimization techniques used by proprietary systems or advanced open-source frameworks. Due to fundamental differences in qubit technologies, efficient compiler design is an expensive process, further exposing these systems to various security threats. In this work, we take a first step toward evaluating one such challenge affecting compiler confidentiality, specifically, reverse-engineering compilation methodologies. We propose a simple ML-based framework to infer underlying optimization techniques by leveraging structural differences observed between original and compiled circuits. The motivation is twofold: (1) enhancing transparency in circuit optimization for improved cross-platform debugging and performance tuning, and (2) identifying potential intellectual property (IP)-protected optimizations employed by commercial systems. Our extensive evaluation across thousands of quantum circuits shows that a neural network performs the best in detecting optimization passes, with individual pass F1-scores reaching as high as 0.96. Thus, our initial study demonstrates the viability of this threat to compiler confidentiality and underscores the need for active research in this area.
Adversarial Poisoning Attack on Quantum Machine Learning Models
Nov 22, 2024With the growing interest in Quantum Machine Learning (QML) and the increasing availability of quantum computers through cloud providers, addressing the potential security risks associated with QML has become an urgent priority. One key concern in the QML domain is the threat of data poisoning attacks in the current quantum cloud setting. Adversarial access to training data could severely compromise the integrity and availability of QML models. Classical data poisoning techniques require significant knowledge and training to generate poisoned data, and lack noise resilience, making them ineffective for QML models in the Noisy Intermediate Scale Quantum (NISQ) era. In this work, we first propose a simple yet effective technique to measure intra-class encoder state similarity (ESS) by analyzing the outputs of encoding circuits. Leveraging this approach, we introduce a quantum indiscriminate data poisoning attack, QUID. Through extensive experiments conducted in both noiseless and noisy environments (e.g., IBM\_Brisbane's noise), across various architectures and datasets, QUID achieves up to $92\%$ accuracy degradation in model performance compared to baseline models and up to $75\%$ accuracy degradation compared to random label-flipping. We also tested QUID against state-of-the-art classical defenses, with accuracy degradation still exceeding $50\%$, demonstrating its effectiveness. This work represents the first attempt to reevaluate data poisoning attacks in the context of QML.
Security Concerns in Quantum Machine Learning as a Service
Aug 18, 2024Quantum machine learning (QML) is a category of algorithms that employ variational quantum circuits (VQCs) to tackle machine learning tasks. Recent discoveries have shown that QML models can effectively generalize from limited training data samples. This capability has sparked increased interest in deploying these models to address practical, real-world challenges, resulting in the emergence of Quantum Machine Learning as a Service (QMLaaS). QMLaaS represents a hybrid model that utilizes both classical and quantum computing resources. Classical computers play a crucial role in this setup, handling initial pre-processing and subsequent post-processing of data to compensate for the current limitations of quantum hardware. Since this is a new area, very little work exists to paint the whole picture of QMLaaS in the context of known security threats in the domain of classical and quantum machine learning. This SoK paper is aimed to bridge this gap by outlining the complete QMLaaS workflow, which encompasses both the training and inference phases and highlighting significant security concerns involving untrusted classical or quantum providers. QML models contain several sensitive assets, such as the model architecture, training/testing data, encoding techniques, and trained parameters. Unauthorized access to these components could compromise the model's integrity and lead to intellectual property (IP) theft. We pinpoint the critical security issues that must be considered to pave the way for a secure QMLaaS deployment.
STIQ: Safeguarding Training and Inferencing of Quantum Neural Networks from Untrusted Cloud
May 29, 2024



The high expenses imposed by current quantum cloud providers, coupled with the escalating need for quantum resources, may incentivize the emergence of cheaper cloud-based quantum services from potentially untrusted providers. Deploying or hosting quantum models, such as Quantum Neural Networks (QNNs), on these untrusted platforms introduces a myriad of security concerns, with the most critical one being model theft. This vulnerability stems from the cloud provider's full access to these circuits during training and/or inference. In this work, we introduce STIQ, a novel ensemble-based strategy designed to safeguard QNNs against such cloud-based adversaries. Our method innovatively trains two distinct QNNs concurrently, hosting them on same or different platforms, in a manner that each network yields obfuscated outputs rendering the individual QNNs ineffective for adversaries operating within cloud environments. However, when these outputs are combined locally (using an aggregate function), they reveal the correct result. Through extensive experiments across various QNNs and datasets, our technique has proven to effectively masks the accuracy and losses of the individually hosted models by upto 76\%, albeit at the expense of $\leq 2\times$ increase in the total computational overhead. This trade-off, however, is a small price to pay for the enhanced security and integrity of QNNs in a cloud-based environment prone to untrusted adversaries. We also demonstrated STIQ's practical application by evaluating it on real 127-qubit IBM\_Sherbrooke hardware, showing that STIQ achieves up to 60\% obfuscation, with combined performance comparable to an unobfuscated model.
Evaluating Efficacy of Model Stealing Attacks and Defenses on Quantum Neural Networks
Feb 18, 2024Cloud hosting of quantum machine learning (QML) models exposes them to a range of vulnerabilities, the most significant of which is the model stealing attack. In this study, we assess the efficacy of such attacks in the realm of quantum computing. We conducted comprehensive experiments on various datasets with multiple QML model architectures. Our findings revealed that model stealing attacks can produce clone models achieving up to $0.9\times$ and $0.99\times$ clone test accuracy when trained using Top-$1$ and Top-$k$ labels, respectively ($k:$ num\_classes). To defend against these attacks, we leverage the unique properties of current noisy hardware and perturb the victim model outputs and hinder the attacker's training process. In particular, we propose: 1) hardware variation-induced perturbation (HVIP) and 2) hardware and architecture variation-induced perturbation (HAVIP). Although noise and architectural variability can provide up to $\sim16\%$ output obfuscation, our comprehensive analysis revealed that models cloned under noisy conditions tend to be resilient, suffering little to no performance degradation due to such obfuscations. Despite limited success with our defense techniques, this outcome has led to an important discovery: QML models trained on noisy hardwares are naturally resistant to perturbation or obfuscation-based defenses or attacks.
WEPRO: Weight Prediction for Efficient Optimization of Hybrid Quantum-Classical Algorithms
Aug 09, 2023The exponential run time of quantum simulators on classical machines and long queue depths and high costs of real quantum devices present significant challenges in the effective training of Variational Quantum Algorithms (VQAs) like Quantum Neural Networks (QNNs), Variational Quantum Eigensolver (VQE) and Quantum Approximate Optimization Algorithm (QAOA). To address these limitations, we propose a new approach, WEPRO (Weight Prediction), which accelerates the convergence of VQAs by exploiting regular trends in the parameter weights. We introduce two techniques for optimal prediction performance namely, Naive Prediction (NaP) and Adaptive Prediction (AdaP). Through extensive experimentation and training of multiple QNN models on various datasets, we demonstrate that WEPRO offers a speedup of approximately $2.25\times$ compared to standard training methods, while also providing improved accuracy (up to $2.3\%$ higher) and loss (up to $6.1\%$ lower) with low storage and computational overheads. We also evaluate WEPRO's effectiveness in VQE for molecular ground-state energy estimation and in QAOA for graph MaxCut. Our results show that WEPRO leads to speed improvements of up to $3.1\times$ for VQE and $2.91\times$ for QAOA, compared to traditional optimization techniques, while using up to $3.3\times$ less number of shots (i.e., repeated circuit executions) per training iteration.
Quantum Machine Learning for Material Synthesis and Hardware Security
Aug 16, 2022
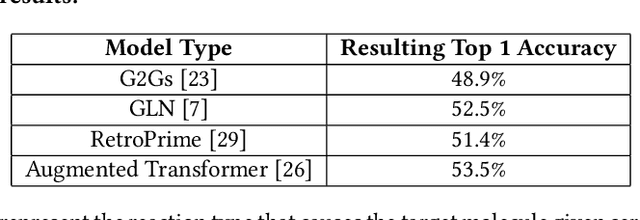
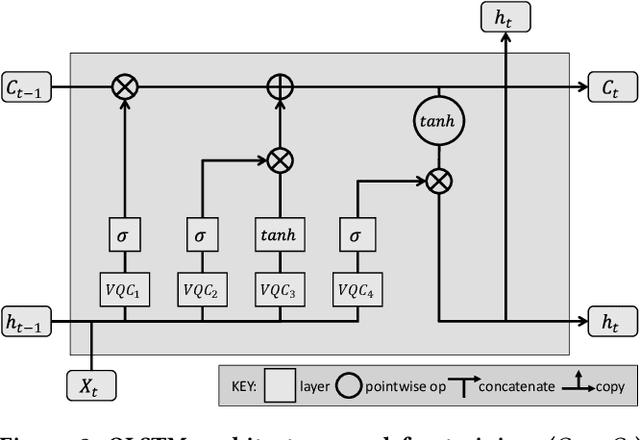

Using quantum computing, this paper addresses two scientifically pressing and day-to-day relevant problems, namely, chemical retrosynthesis which is an important step in drug/material discovery and security of the semiconductor supply chain. We show that Quantum Long Short-Term Memory (QLSTM) is a viable tool for retrosynthesis. We achieve 65% training accuracy with QLSTM, whereas classical LSTM can achieve 100%. However, in testing, we achieve 80% accuracy with the QLSTM while classical LSTM peaks at only 70% accuracy! We also demonstrate an application of Quantum Neural Network (QNN) in the hardware security domain, specifically in Hardware Trojan (HT) detection using a set of power and area Trojan features. The QNN model achieves detection accuracy as high as 97.27%.
Security Aspects of Quantum Machine Learning: Opportunities, Threats and Defenses
Apr 07, 2022
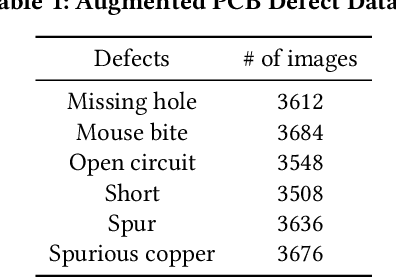
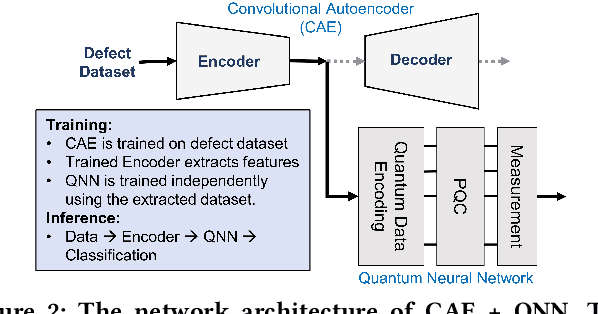
In the last few years, quantum computing has experienced a growth spurt. One exciting avenue of quantum computing is quantum machine learning (QML) which can exploit the high dimensional Hilbert space to learn richer representations from limited data and thus can efficiently solve complex learning tasks. Despite the increased interest in QML, there have not been many studies that discuss the security aspects of QML. In this work, we explored the possible future applications of QML in the hardware security domain. We also expose the security vulnerabilities of QML and emerging attack models, and corresponding countermeasures.
Quantum-Classical Hybrid Machine Learning for Image Classification (ICCAD Special Session Paper)
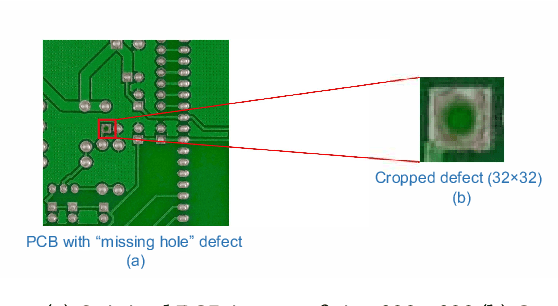
Sep 17, 2021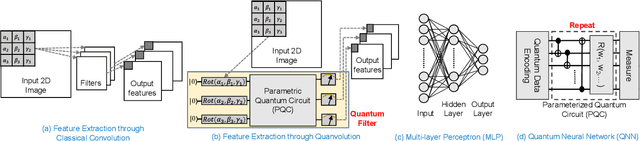
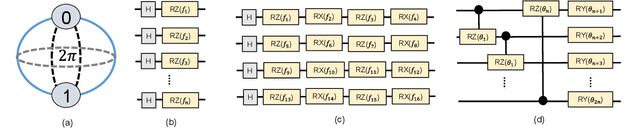
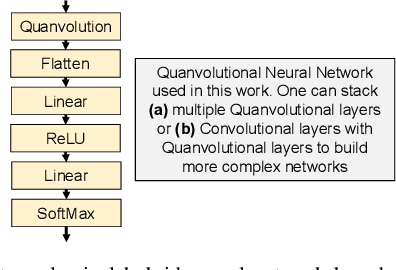
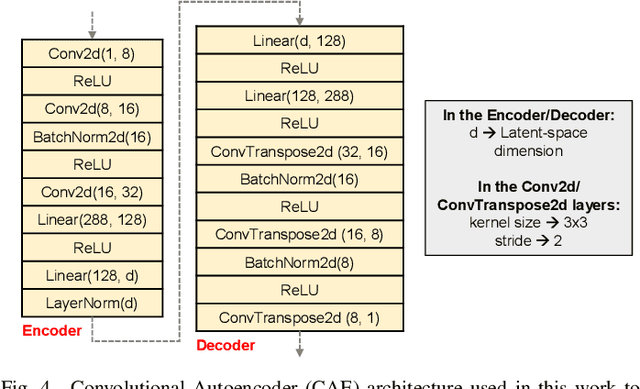
Image classification is a major application domain for conventional deep learning (DL). Quantum machine learning (QML) has the potential to revolutionize image classification. In any typical DL-based image classification, we use convolutional neural network (CNN) to extract features from the image and multi-layer perceptron network (MLP) to create the actual decision boundaries. On one hand, QML models can be useful in both of these tasks. Convolution with parameterized quantum circuits (Quanvolution) can extract rich features from the images. On the other hand, quantum neural network (QNN) models can create complex decision boundaries. Therefore, Quanvolution and QNN can be used to create an end-to-end QML model for image classification. Alternatively, we can extract image features separately using classical dimension reduction techniques such as, Principal Components Analysis (PCA) or Convolutional Autoencoder (CAE) and use the extracted features to train a QNN. We review two proposals on quantum-classical hybrid ML models for image classification namely, Quanvolutional Neural Network and dimension reduction using a classical algorithm followed by QNN. Particularly, we make a case for trainable filters in Quanvolution and CAE-based feature extraction for image datasets (instead of dimension reduction using linear transformations such as, PCA). We discuss various design choices, potential opportunities, and drawbacks of these models. We also release a Python-based framework to create and explore these hybrid models with a variety of design choices.