 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemgcpy: A Comprehensive High Dimensional Independence Testing Python Package
Jul 18, 2019
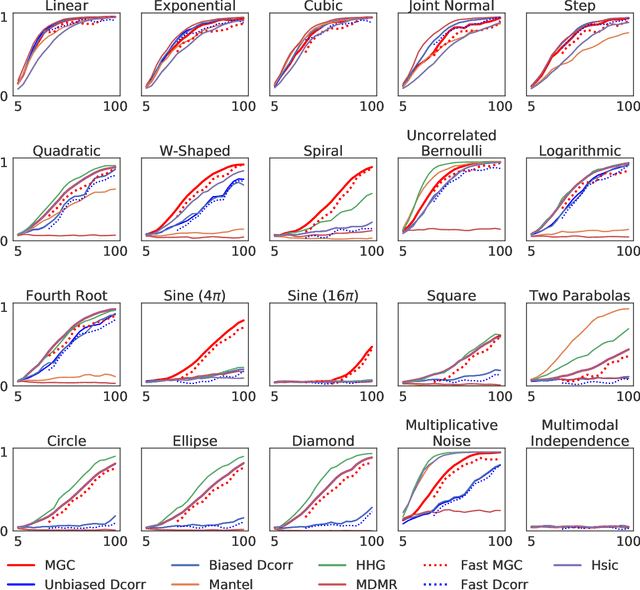
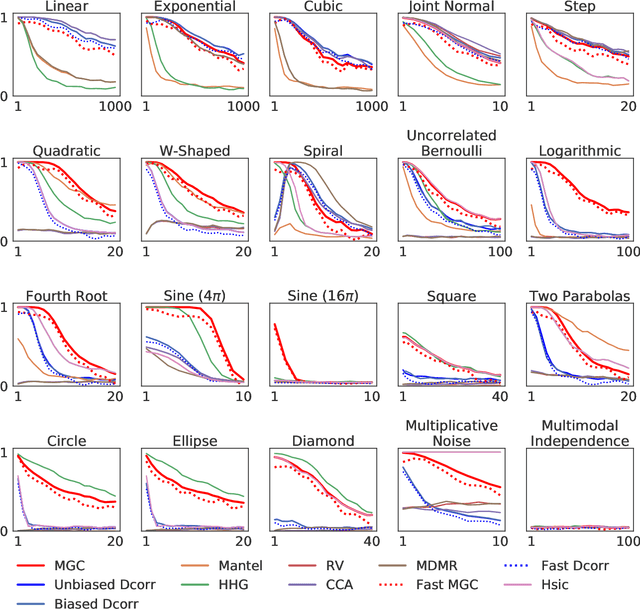
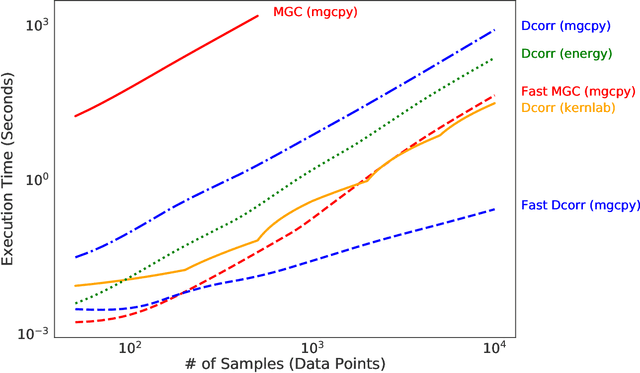
With the increase in the amount of data in many fields, a method to consistently and efficiently decipher relationships within high dimensional data sets is important. Because many modern datasets are high-dimensional, univariate independence tests are not applicable. While many multivariate independence tests have R packages available, the interfaces are inconsistent, most are not available in Python. mgcpy is an extensive Python library that includes many state of the art high-dimensional independence testing procedures using a common interface. The package is easy-to-use and is flexible enough to enable future extensions. This manuscript provides details for each of the tests as well as extensive power and run-time benchmarks on a suite of high-dimensional simulations previously used in different publications. The appendix includes demonstrations of how the user can interact with the package, as well as links and documentation.
Deep Learning the Indus Script
Feb 02, 2017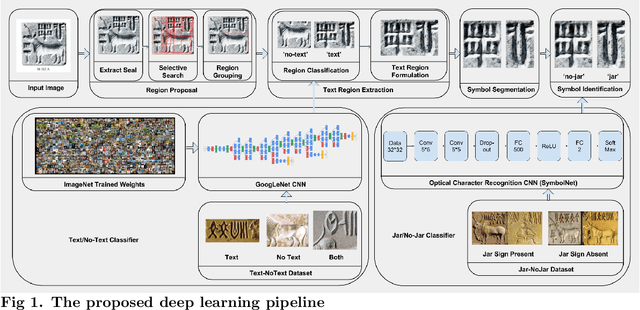

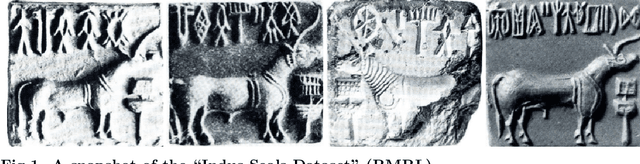

Standardized corpora of undeciphered scripts, a necessary starting point for computational epigraphy, requires laborious human effort for their preparation from raw archaeological records. Automating this process through machine learning algorithms can be of significant aid to epigraphical research. Here, we take the first steps in this direction and present a deep learning pipeline that takes as input images of the undeciphered Indus script, as found in archaeological artifacts, and returns as output a string of graphemes, suitable for inclusion in a standard corpus. The image is first decomposed into regions using Selective Search and these regions are classified as containing textual and/or graphical information using a convolutional neural network. Regions classified as potentially containing text are hierarchically merged and trimmed to remove non-textual information. The remaining textual part of the image is segmented using standard image processing techniques to isolate individual graphemes. This set is finally passed to a second convolutional neural network to classify the graphemes, based on a standard corpus. The classifier can identify the presence or absence of the most frequent Indus grapheme, the "jar" sign, with an accuracy of 92%. Our results demonstrate the great potential of deep learning approaches in computational epigraphy and, more generally, in the digital humanities.