 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel State Value Network for Combined Prediction and Planning in Interactive Environments
Oct 11, 2023



Automated vehicles operating in urban environments have to reliably interact with other traffic participants. Planning algorithms often utilize separate prediction modules forecasting probabilistic, multi-modal, and interactive behaviors of objects. Designing prediction and planning as two separate modules introduces significant challenges, particularly due to the interdependence of these modules. This work proposes a deep learning methodology to combine prediction and planning. A conditional GAN with the U-Net architecture is trained to predict two high-resolution image sequences. The sequences represent explicit motion predictions, mainly used to train context understanding, and pixel state values suitable for planning encoding kinematic reachability, object dynamics, safety, and driving comfort. The model can be trained offline on target images rendered by a sampling-based model-predictive planner, leveraging real-world driving data. Our results demonstrate intuitive behavior in complex situations, such as lane changes amidst conflicting objectives.
Planning on the fast lane: Learning to interact using attention mechanisms in path integral inverse reinforcement learning
Jul 11, 2020
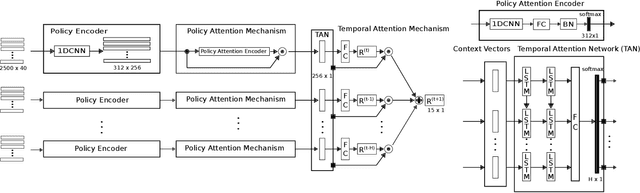
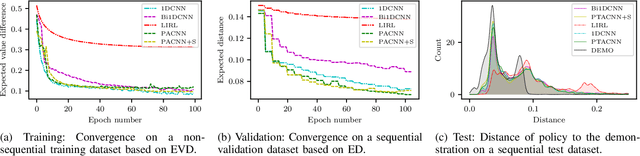
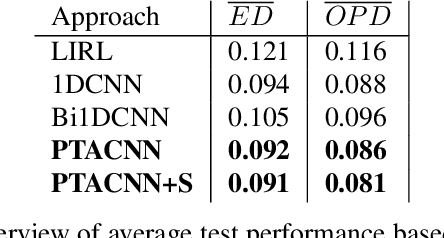
General-purpose trajectory planning algorithms for automated driving utilize complex reward functions to perform a combined optimization of strategic, behavioral, and kinematic features. The specification and tuning of a single reward function is a tedious task and does not generalize over a large set of traffic situations. Deep learning approaches based on path integral inverse reinforcement learning have been successfully applied to predict local situation-dependent reward functions using features of a set of sampled driving policies. Sample-based trajectory planning algorithms are able to approximate a spatio-temporal subspace of feasible driving policies that can be used to encode the context of a situation. However, the interaction with dynamic objects requires an extended planning horizon, which requires sequential context modeling. In this work, we are concerned with the sequential reward prediction over an extended time horizon. We present a neural network architecture that uses a policy attention mechanism to generate a low-dimensional context vector by concentrating on trajectories with a human-like driving style. Besides, we propose a temporal attention mechanism to identify context switches and allow for stable adaptation of rewards. We evaluate our results on complex simulated driving situations, including other vehicles. Our evaluation shows that our policy attention mechanisms learns to focus on collision free policies in the configuration space. Furthermore, the temporal attention mechanism learns persistent interaction with other vehicles over an extended planning horizon.
Driving Style Encoder: Situational Reward Adaptation for General-Purpose Planning in Automated Driving
Dec 07, 2019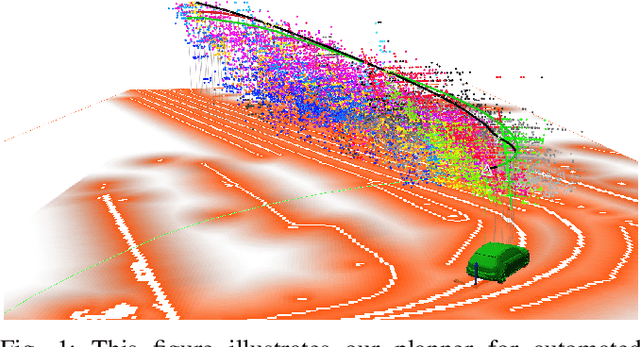
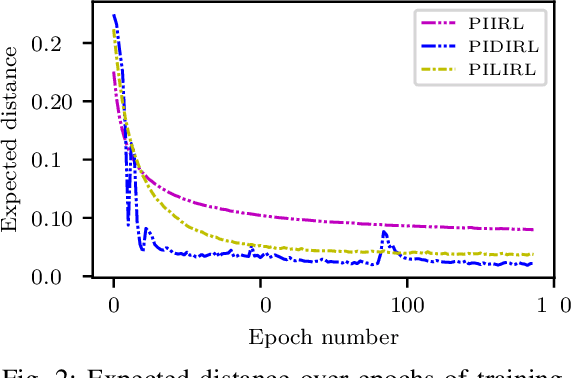

General-purpose planning algorithms for automated driving combine mission, behavior, and local motion planning. Such planning algorithms map features of the environment and driving kinematics into complex reward functions. To achieve this, planning experts often rely on linear reward functions. The specification and tuning of these reward functions is a tedious process and requires significant experience. Moreover, a manually designed linear reward function does not generalize across different driving situations. In this work, we propose a deep learning approach based on inverse reinforcement learning that generates situation-dependent reward functions. Our neural network provides a mapping between features and actions of sampled driving policies of a model-predictive control-based planner and predicts reward functions for upcoming planning cycles. In our evaluation, we compare the driving style of reward functions predicted by our deep network against clustered and linear reward functions. Our proposed deep learning approach outperforms clustered linear reward functions and is at par with linear reward functions with a-priori knowledge about the situation.
Driving with Style: Inverse Reinforcement Learning in General-Purpose Planning for Automated Driving
May 01, 2019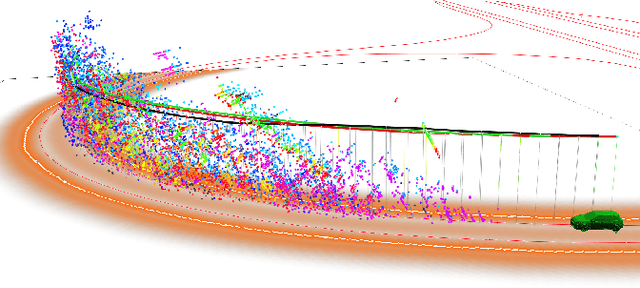
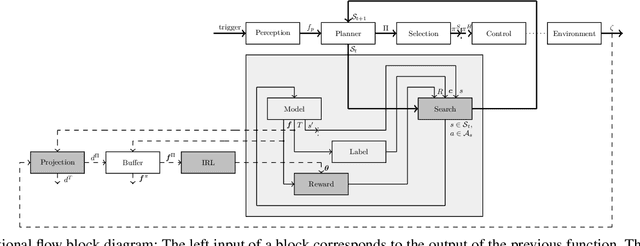
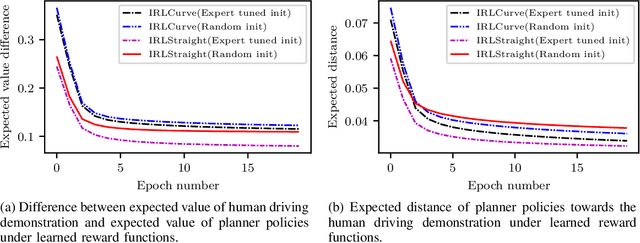
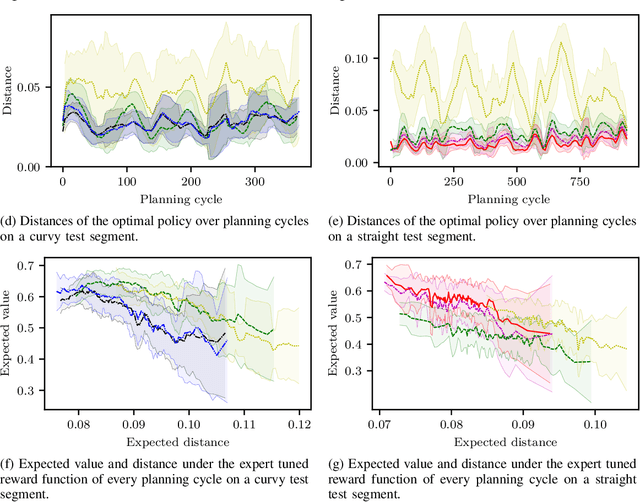
Behavior and motion planning play an important role in automated driving. Traditionally, behavior planners instruct local motion planners with predefined behaviors. Due to the high scene complexity in urban environments, unpredictable situations may occur in which behavior planners fail to match predefined behavior templates. Recently, general-purpose planners have been introduced, combining behavior and local motion planning. These general-purpose planners allow behavior-aware motion planning given a single reward function. However, two challenges arise: First, this function has to map a complex feature space into rewards. Second, the reward function has to be manually tuned by an expert. Manually tuning this reward function becomes a tedious task. In this paper, we propose an approach that relies on human driving demonstrations to automatically tune reward functions. This study offers important insights into the driving style optimization of general-purpose planners with maximum entropy inverse reinforcement learning. We evaluate our approach based on the expected value difference between learned and demonstrated policies. Furthermore, we compare the similarity of human driven trajectories with optimal policies of our planner under learned and expert-tuned reward functions. Our experiments show that we are able to learn reward functions exceeding the level of manual expert tuning without prior domain knowledge.