 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSambaMixer: State of Health Prediction of Li-ion Batteries using Mamba State Space Models
Oct 31, 2024



The state of health (SOH) of a Li-ion battery is a critical parameter that determines the remaining capacity and the remaining lifetime of the battery. In this paper, we propose SambaMixer a novel structured state space model (SSM) for predicting the state of health of Li-ion batteries. The proposed SSM is based on the MambaMixer architecture, which is designed to handle multi-variate time signals. We evaluate our model on the NASA battery discharge dataset and show that our model outperforms the state-of-the-art on this dataset. We further introduce a novel anchor-based resampling method which ensures time signals are of the expected length while also serving as augmentation technique. Finally, we condition prediction on the sample time and the cycle time difference using positional encodings to improve the performance of our model and to learn recuperation effects. Our results proof that our model is able to predict the SOH of Li-ion batteries with high accuracy and robustness.
RGB-D-Fusion: Image Conditioned Depth Diffusion of Humanoid Subjects
Jul 29, 2023We present RGB-D-Fusion, a multi-modal conditional denoising diffusion probabilistic model to generate high resolution depth maps from low-resolution monocular RGB images of humanoid subjects. RGB-D-Fusion first generates a low-resolution depth map using an image conditioned denoising diffusion probabilistic model and then upsamples the depth map using a second denoising diffusion probabilistic model conditioned on a low-resolution RGB-D image. We further introduce a novel augmentation technique, depth noise augmentation, to increase the robustness of our super-resolution model.
VoloGAN: Adversarial Domain Adaptation for Synthetic Depth Data
Jul 19, 2022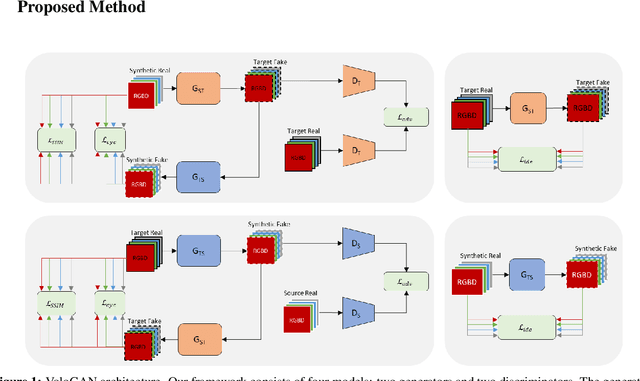

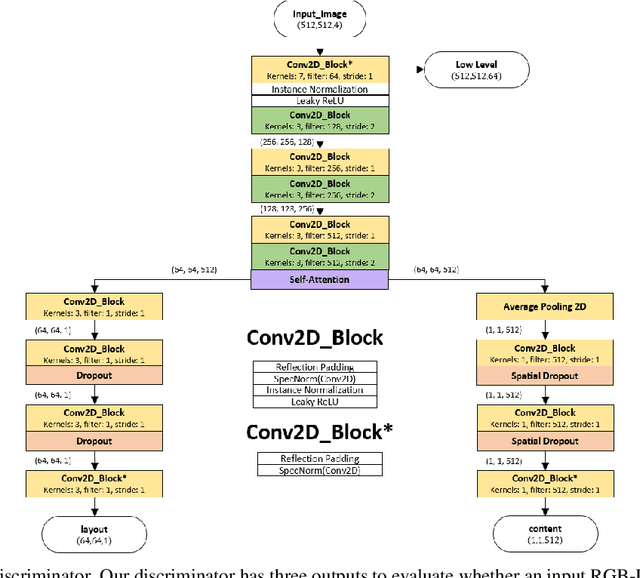
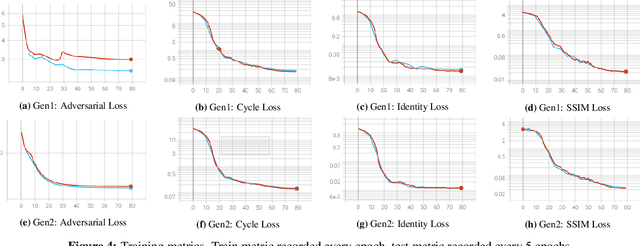
We present VoloGAN, an adversarial domain adaptation network that translates synthetic RGB-D images of a high-quality 3D model of a person, into RGB-D images that could be generated with a consumer depth sensor. This system is especially useful to generate high amount training data for single-view 3D reconstruction algorithms replicating the real-world capture conditions, being able to imitate the style of different sensor types, for the same high-end 3D model database. The network uses a CycleGAN framework with a U-Net architecture for the generator and a discriminator inspired by SIV-GAN. We use different optimizers and learning rate schedules to train the generator and the discriminator. We further construct a loss function that considers image channels individually and, among other metrics, evaluates the structural similarity. We demonstrate that CycleGANs can be used to apply adversarial domain adaptation of synthetic 3D data to train a volumetric video generator model having only few training samples.