 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review on Understanding the Decentralized and Collaborative Approach in Machine Learning
Mar 12, 2025



The arrival of Machine Learning (ML) completely changed how we can unlock valuable information from data. Traditional methods, where everything was stored in one place, had big problems with keeping information private, handling large amounts of data, and avoiding unfair advantages. Machine Learning has become a powerful tool that uses Artificial Intelligence (AI) to overcome these challenges. We started by learning the basics of Machine Learning, including the different types like supervised, unsupervised, and reinforcement learning. We also explored the important steps involved, such as preparing the data, choosing the right model, training it, and then checking its performance. Next, we examined some key challenges in Machine Learning, such as models learning too much from specific examples (overfitting), not learning enough (underfitting), and reflecting biases in the data used. Moving beyond centralized systems, we looked at decentralized Machine Learning and its benefits, like keeping data private, getting answers faster, and using a wider variety of data sources. We then focused on a specific type called federated learning, where models are trained without directly sharing sensitive information. Real-world examples from healthcare and finance were used to show how collaborative Machine Learning can solve important problems while still protecting information security. Finally, we discussed challenges like communication efficiency, dealing with different types of data, and security. We also explored using a Zero Trust framework, which provides an extra layer of protection for collaborative Machine Learning systems. This approach is paving the way for a bright future for this groundbreaking technology.
Principles and Components of Federated Learning Architectures
Feb 07, 2025Federated learning, also known as FL, is a machine learning framework in which a significant amount of clients (such as mobile devices or whole enterprises) collaborate to collaboratively train a model while keeping decentralized training data, all overseen by a central server (such as a service provider). There are advantages in terms of privacy, security, regulations, and economy with this decentralized approach to model training. FL is not impervious to the flaws that plague conventional machine learning models, despite its seeming promise. This study offers a thorough analysis of the fundamental ideas and elements of federated learning architectures, emphasizing five important areas: communication architectures, machine learning models, data partitioning, privacy methods, and system heterogeneity. We additionally address the difficulties and potential paths for future study in the area. Furthermore, based on a comprehensive review of the literature, we present a collection of architectural patterns for federated learning systems. This analysis will help to understand the basic of Federated learning, the primary components of FL, and also about several architectural details.
Online learning for X-ray, CT or MRI
Jun 10, 2023Medical imaging plays an important role in the medical sector in identifying diseases. X-ray, computed tomography (CT) scans, and magnetic resonance imaging (MRI) are a few examples of medical imaging. Most of the time, these imaging techniques are utilized to examine and diagnose diseases. Medical professionals identify the problem after analyzing the images. However, manual identification can be challenging because the human eye is not always able to recognize complex patterns in an image. Because of this, it is difficult for any professional to recognize a disease with rapidity and accuracy. In recent years, medical professionals have started adopting Computer-Aided Diagnosis (CAD) systems to evaluate medical images. This system can analyze the image and detect the disease very precisely and quickly. However, this system has certain drawbacks in that it needs to be processed before analysis. Medical research is already entered a new era of research which is called Artificial Intelligence (AI). AI can automatically find complex patterns from an image and identify diseases. Methods for medical imaging that uses AI techniques will be covered in this chapter.
A Survey of Recommender System Techniques and the Ecommerce Domain
Aug 15, 2022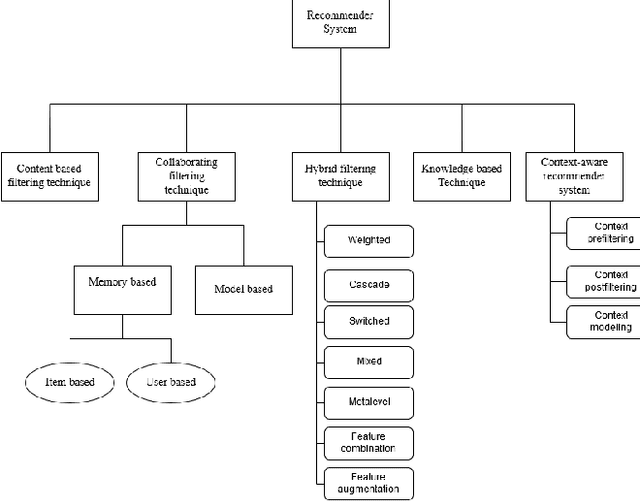

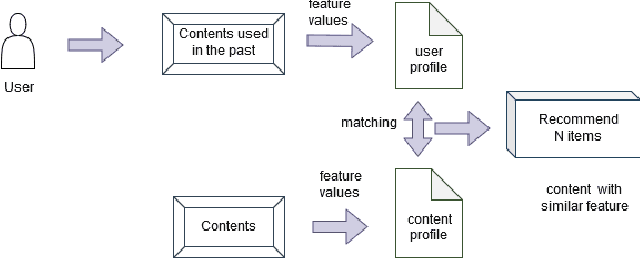
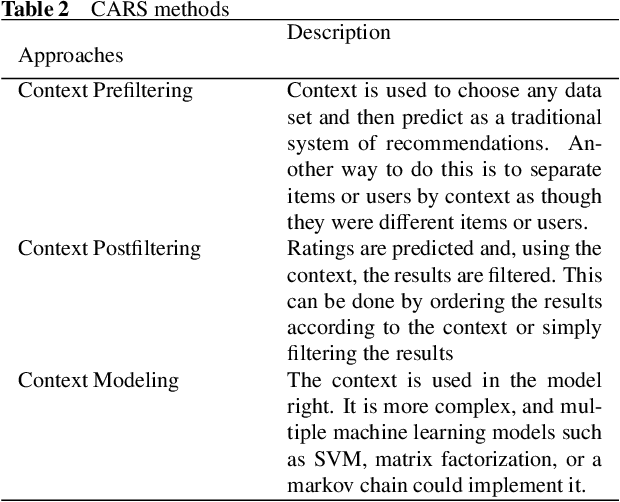
In this big data era, it is hard for the current generation to find the right data from the huge amount of data contained within online platforms. In such a situation, there is a need for an information filtering system that might help them find the information they are looking for. In recent years, a research field has emerged known as recommender systems. Recommenders have become important as they have many real-life applications. This paper reviews the different techniques and developments of recommender systems in e-commerce, e-tourism, e-resources, e-government, e-learning, and e-library. By analyzing recent work on this topic, we will be able to provide a detailed overview of current developments and identify existing difficulties in recommendation systems. The final results give practitioners and researchers the necessary guidance and insights into the recommendation system and its application.