 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian Rhetorical Structure Theory
Jun 25, 2021
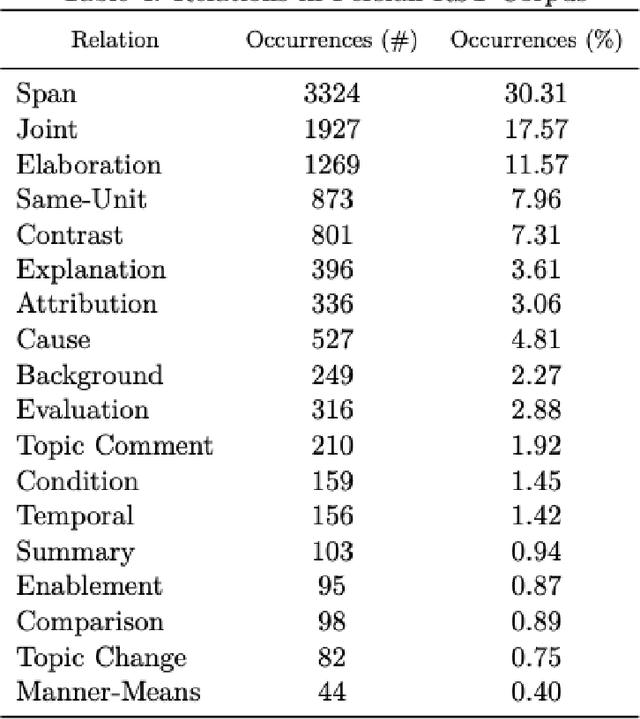
Over the past years, interest in discourse analysis and discourse parsing has steadily grown, and many discourse-annotated corpora and, as a result, discourse parsers have been built. In this paper, we present a discourse-annotated corpus for the Persian language built in the framework of Rhetorical Structure Theory as well as a discourse parser built upon the DPLP parser, an open-source discourse parser. Our corpus consists of 150 journalistic texts, each text having an average of around 400 words. Corpus texts were annotated using 18 discourse relations and based on the annotation guideline of the English RST Discourse Treebank corpus. Our text-level discourse parser is trained using gold segmentation and is built upon the DPLP discourse parser, which uses a large-margin transition-based approach to solve the problem of discourse parsing. The performance of our discourse parser in span (S), nuclearity (N) and relation (R) detection is around 78%, 64%, 44% respectively, in terms of F1 measure.