 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Non-Functional Requirements Generation in Software Engineering with Large Language Models: A Comparative Study
Mar 19, 2025Neglecting non-functional requirements (NFRs) early in software development can lead to critical challenges. Despite their importance, NFRs are often overlooked or difficult to identify, impacting software quality. To support requirements engineers in eliciting NFRs, we developed a framework that leverages Large Language Models (LLMs) to derive quality-driven NFRs from functional requirements (FRs). Using a custom prompting technique within a Deno-based pipeline, the system identifies relevant quality attributes for each functional requirement and generates corresponding NFRs, aiding systematic integration. A crucial aspect is evaluating the quality and suitability of these generated requirements. Can LLMs produce high-quality NFR suggestions? Using 34 functional requirements - selected as a representative subset of 3,964 FRs-the LLMs inferred applicable attributes based on the ISO/IEC 25010:2023 standard, generating 1,593 NFRs. A horizontal evaluation covered three dimensions: NFR validity, applicability of quality attributes, and classification precision. Ten industry software quality evaluators, averaging 13 years of experience, assessed a subset for relevance and quality. The evaluation showed strong alignment between LLM-generated NFRs and expert assessments, with median validity and applicability scores of 5.0 (means: 4.63 and 4.59, respectively) on a 1-5 scale. In the classification task, 80.4% of LLM-assigned attributes matched expert choices, with 8.3% near misses and 11.3% mismatches. A comparative analysis of eight LLMs highlighted variations in performance, with gemini-1.5-pro exhibiting the highest attribute accuracy, while llama-3.3-70B achieved higher validity and applicability scores. These findings provide insights into the feasibility of using LLMs for automated NFR generation and lay the foundation for further exploration of AI-assisted requirements engineering.
LLM4DS: Evaluating Large Language Models for Data Science Code Generation
Nov 16, 2024
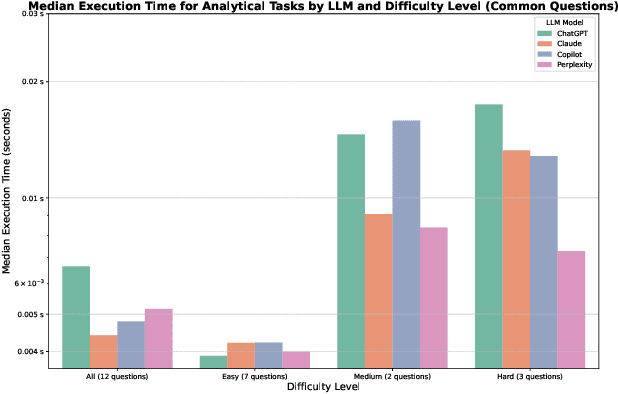


The adoption of Large Language Models (LLMs) for code generation in data science offers substantial potential for enhancing tasks such as data manipulation, statistical analysis, and visualization. However, the effectiveness of these models in the data science domain remains underexplored. This paper presents a controlled experiment that empirically assesses the performance of four leading LLM-based AI assistants-Microsoft Copilot (GPT-4 Turbo), ChatGPT (o1-preview), Claude (3.5 Sonnet), and Perplexity Labs (Llama-3.1-70b-instruct)-on a diverse set of data science coding challenges sourced from the Stratacratch platform. Using the Goal-Question-Metric (GQM) approach, we evaluated each model's effectiveness across task types (Analytical, Algorithm, Visualization) and varying difficulty levels. Our findings reveal that all models exceeded a 50% baseline success rate, confirming their capability beyond random chance. Notably, only ChatGPT and Claude achieved success rates significantly above a 60% baseline, though none of the models reached a 70% threshold, indicating limitations in higher standards. ChatGPT demonstrated consistent performance across varying difficulty levels, while Claude's success rate fluctuated with task complexity. Hypothesis testing indicates that task type does not significantly impact success rate overall. For analytical tasks, efficiency analysis shows no significant differences in execution times, though ChatGPT tended to be slower and less predictable despite high success rates. This study provides a structured, empirical evaluation of LLMs in data science, delivering insights that support informed model selection tailored to specific task demands. Our findings establish a framework for future AI assessments, emphasizing the value of rigorous evaluation beyond basic accuracy measures.