 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLikelihood-based semi-supervised model selection with applications to speech processing
Nov 20, 2009


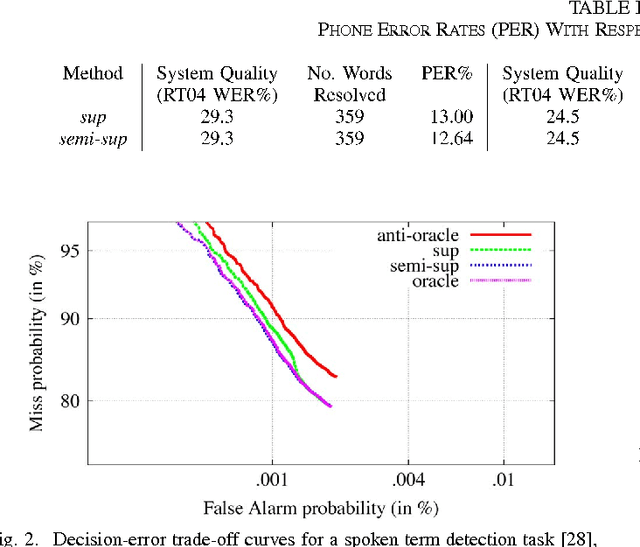
In conventional supervised pattern recognition tasks, model selection is typically accomplished by minimizing the classification error rate on a set of so-called development data, subject to ground-truth labeling by human experts or some other means. In the context of speech processing systems and other large-scale practical applications, however, such labeled development data are typically costly and difficult to obtain. This article proposes an alternative semi-supervised framework for likelihood-based model selection that leverages unlabeled data by using trained classifiers representing each model to automatically generate putative labels. The errors that result from this automatic labeling are shown to be amenable to results from robust statistics, which in turn provide for minimax-optimal censored likelihood ratio tests that recover the nonparametric sign test as a limiting case. This approach is then validated experimentally using a state-of-the-art automatic speech recognition system to select between candidate word pronunciations using unlabeled speech data that only potentially contain instances of the words under test. Results provide supporting evidence for the utility of this approach, and suggest that it may also find use in other applications of machine learning.
* 11 pages, 2 figures; submitted for publication