 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn efficient likelihood-free Bayesian inference method based on sequential neural posterior estimation
Nov 27, 2023Sequential neural posterior estimation (SNPE) techniques have been recently proposed for dealing with simulation-based models with intractable likelihoods. Unlike approximate Bayesian computation, SNPE techniques learn the posterior from sequential simulation using neural network-based conditional density estimators by minimizing a specific loss function. The SNPE method proposed by Lueckmann et al. (2017) used a calibration kernel to boost the sample weights around the observed data, resulting in a concentrated loss function. However, the use of calibration kernels may increase the variances of both the empirical loss and its gradient, making the training inefficient. To improve the stability of SNPE, this paper proposes to use an adaptive calibration kernel and several variance reduction techniques. The proposed method greatly speeds up the process of training, and provides a better approximation of the posterior than the original SNPE method and some existing competitors as confirmed by numerical experiments.
Conditional Density Estimations from Privacy-Protected Data
Oct 20, 2023

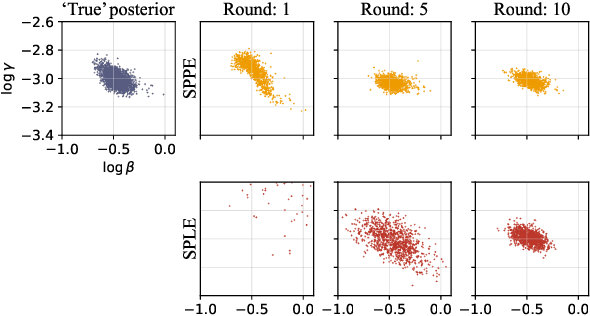
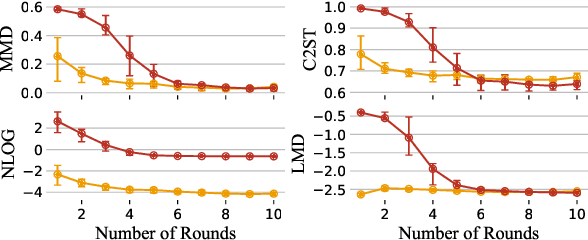
Many modern statistical analysis and machine learning applications require training models on sensitive user data. Differential privacy provides a formal guarantee that individual-level information about users does not leak. In this framework, randomized algorithms inject calibrated noise into the confidential data, resulting in privacy-protected datasets or queries. However, restricting access to only the privatized data during statistical analysis makes it computationally challenging to perform valid inferences on parameters underlying the confidential data. In this work, we propose simulation-based inference methods from privacy-protected datasets. Specifically, we use neural conditional density estimators as a flexible family of distributions to approximate the posterior distribution of model parameters given the observed private query results. We illustrate our methods on discrete time-series data under an infectious disease model and on ordinary linear regression models. Illustrating the privacy-utility trade-off, our experiments and analysis demonstrate the necessity and feasibility of designing valid statistical inference procedures to correct for biases introduced by the privacy-protection mechanisms.