 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Multi-Objective based Parameter Optimization for Deep Learning
May 17, 2023Deep learning models form one of the most powerful machine learning models for the extraction of important features. Most of the designs of deep neural models, i.e., the initialization of parameters, are still manually tuned. Hence, obtaining a model with high performance is exceedingly time-consuming and occasionally impossible. Optimizing the parameters of the deep networks, therefore, requires improved optimization algorithms with high convergence rates. The single objective-based optimization methods generally used are mostly time-consuming and do not guarantee optimum performance in all cases. Mathematical optimization problems containing multiple objective functions that must be optimized simultaneously fall under the category of multi-objective optimization sometimes referred to as Pareto optimization. Multi-objective optimization problems form one of the alternatives yet useful options for parameter optimization. However, this domain is a bit less explored. In this survey, we focus on exploring the effectiveness of multi-objective optimization strategies for parameter optimization in conjunction with deep neural networks. The case studies used in this study focus on how the two methods are combined to provide valuable insights into the generation of predictions and analysis in multiple applications.
IV-GNN : Interval Valued Data Handling Using Graph Neural Network
Nov 17, 2021
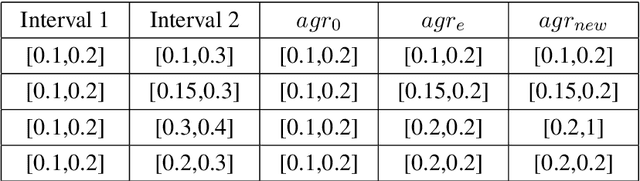

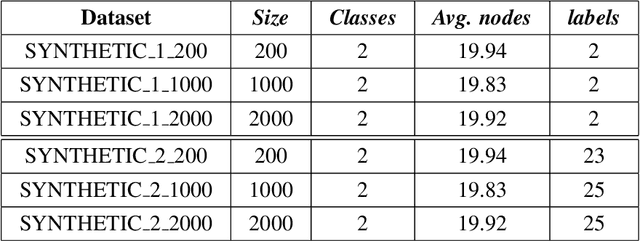
Graph Neural Network (GNN) is a powerful tool to perform standard machine learning on graphs. To have a Euclidean representation of every node in the Non-Euclidean graph-like data, GNN follows neighbourhood aggregation and combination of information recursively along the edges of the graph. Despite having many GNN variants in the literature, no model can deal with graphs having nodes with interval-valued features. This article proposes an Interval-ValuedGraph Neural Network, a novel GNN model where, for the first time, we relax the restriction of the feature space being countable. Our model is much more general than existing models as any countable set is always a subset of the universal set $R^{n}$, which is uncountable. Here, to deal with interval-valued feature vectors, we propose a new aggregation scheme of intervals and show its expressive power to capture different interval structures. We validate our theoretical findings about our model for graph classification tasks by comparing its performance with those of the state-of-the-art models on several benchmark network and synthetic datasets.
Decomposition in Decision and Objective Space for Multi-Modal Multi-Objective Optimization
Jun 04, 2020



Multi-modal multi-objective optimization problems (MMMOPs) have multiple solution vectors mapping to the same objective vector. For MMMOPs, it is important to discover equivalent solutions associated with each point in the Pareto-Front for allowing end-users to make informed decisions. Prevalent multi-objective evolutionary algorithms are incapable of searching for multiple solution subsets, whereas, algorithms designed for MMMOPs demonstrate degraded performance in the objective space. This motivates the design of better algorithms for addressing MMMOPs. The present work highlights the disadvantage of using crowding distance in the decision space when solving MMMOPs. Subsequently, an evolutionary framework, called graph Laplacian based Optimization using Reference vector assisted Decomposition (LORD), is proposed, which is the first algorithm to use decomposition in both objective and decision space for dealing with MMMOPs. Its filtering step is further extended to present LORD-II algorithm, which demonstrates its dynamics on multi-modal many-objective problems. The efficacy of the frameworks are established by comparing their performance on 34 test instances (obtained from the CEC 2019 multi-modal multi-objective test suite) with the state-of-the-art algorithms for MMMOPs and other multi- and many-objective evolutionary algorithms. The manuscript is concluded mentioning the limitations of the proposed frameworks and future directions to design still better algorithms for MMMOPs.
A Many Objective Optimization Approach for Transfer Learning in EEG Classification
Apr 04, 2019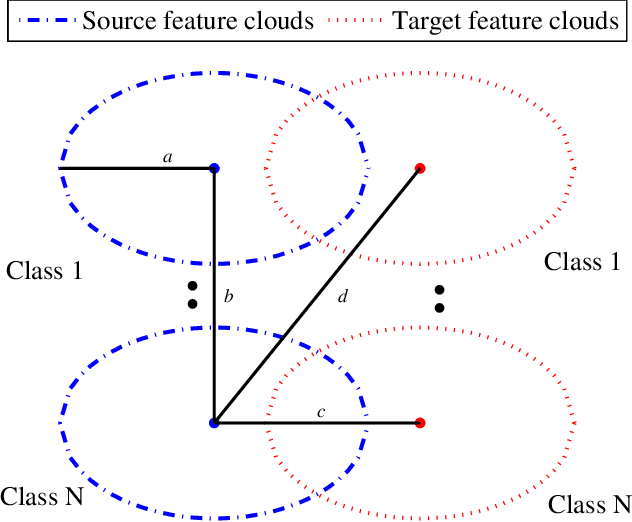
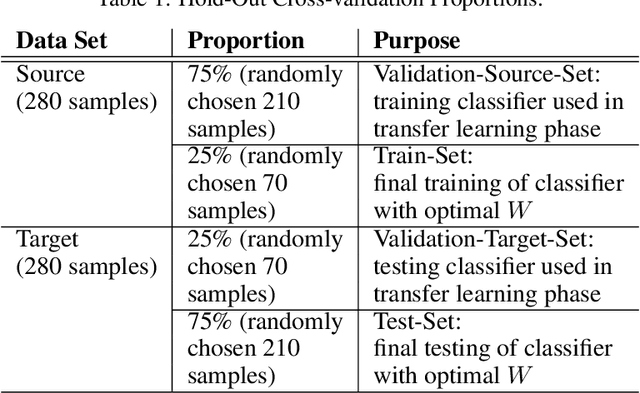
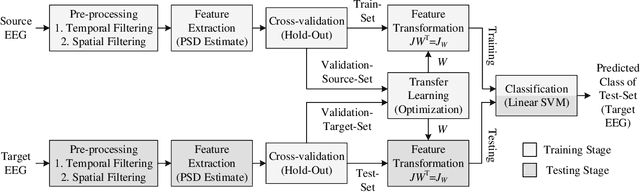
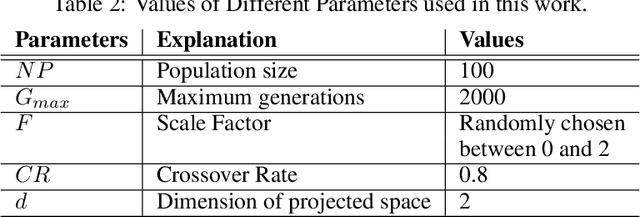
In Brain-Computer Interfacing (BCI), due to inter-subject non-stationarities of electroencephalogram (EEG), classifiers are trained and tested using EEG from the same subject. When physical disabilities bottleneck the natural modality of performing a task, acquisition of ample training data is difficult which practically obstructs classifier training. Previous works have tackled this problem by generalizing the feature space amongst multiple subjects including the test subject. This work aims at knowledge transfer to classify EEG of the target subject using a classifier trained with the EEG of another unit source subject. A many-objective optimization framework is proposed where optimal weights are obtained for projecting features in another dimension such that single source-trained target EEG classification performance is maximized with the modified features. To validate the approach, motor imagery tasks from the BCI Competition III Dataset IVa are classified using power spectral density based features and linear support vector machine. Several performance metrics, improvement in accuracy, sensitivity to the dimension of the projected space, assess the efficacy of the proposed approach. Addressing single-source training promotes independent living of differently-abled individuals by reducing assistance from others. The proposed approach eliminates the requirement of EEG from multiple source subjects and is applicable to any existing feature extractors and classifiers. Source code is available at http://worksupplements.droppages.com/tlbci.html.
conLSH: Context based Locality Sensitive Hashing for Mapping of noisy SMRT Reads
Mar 11, 2019



Single Molecule Real-Time (SMRT) sequencing is a recent advancement of Next Gen technology developed by Pacific Bio (PacBio). It comes with an explosion of long and noisy reads demanding cutting edge research to get most out of it. To deal with the high error probability of SMRT data, a novel contextual Locality Sensitive Hashing (conLSH) based algorithm is proposed in this article, which can effectively align the noisy SMRT reads to the reference genome. Here, sequences are hashed together based not only on their closeness, but also on similarity of context. The algorithm has $\mathcal{O}(n^{\rho+1})$ space requirement, where $n$ is the number of sequences in the corpus and $\rho$ is a constant. The indexing time and querying time are bounded by $\mathcal{O}( \frac{n^{\rho+1} \cdot \ln n}{\ln \frac{1}{P_2}})$ and $\mathcal{O}(n^\rho)$ respectively, where $P_2 > 0$, is a probability value. This algorithm is particularly useful for retrieving similar sequences, a widely used task in biology. The proposed conLSH based aligner is compared with rHAT, popularly used for aligning SMRT reads, and is found to comprehensively beat it in speed as well as in memory requirements. In particular, it takes approximately $24.2\%$ less processing time, while saving about $70.3\%$ in peak memory requirement for H.sapiens PacBio dataset.
An Improved Video Analysis using Context based Extension of LSH
May 29, 2018Locality Sensitive Hashing (LSH) based algorithms have already shown their promise in finding approximate nearest neighbors in high dimen- sional data space. However, there are certain scenarios, as in sequential data, where the proximity of a pair of points cannot be captured without considering their surroundings or context. In videos, as for example, a particular frame is meaningful only when it is seen in the context of its preceding and following frames. LSH has no mechanism to handle the con- texts of the data points. In this article, a novel scheme of Context based Locality Sensitive Hashing (conLSH) has been introduced, in which points are hashed together not only based on their closeness, but also because of similar context. The contribution made in this article is three fold. First, conLSH is integrated with a recently proposed fast optimal sequence alignment algorithm (FOGSAA) using a layered approach. The resultant method is applied to video retrieval for extracting similar sequences. The pro- posed algorithm yields more than 80% accuracy on an average in different datasets. It has been found to save 36.3% of the total time, consumed by the exhaustive search. conLSH reduces the search space to approximately 42% of the entire dataset, when compared with an exhaustive search by the aforementioned FOGSAA, Bag of Words method and the standard LSH implementations. Secondly, the effectiveness of conLSH is demon- strated in action recognition of the video clips, which yields an average gain of 12.83% in terms of classification accuracy over the state of the art methods using STIP descriptors. The last but of great significance is that this article provides a way of automatically annotating long and composite real life videos. The source code of conLSH is made available at http://www.isical.ac.in/~bioinfo_miu/conLSH/conLSH.html