 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirroring the Mind: Distilling Human-Like Metacognitive Strategies into Large Language Models
Feb 26, 2026Large Reasoning Models (LRMs) often exhibit structural fragility in complex reasoning tasks, failing to produce correct answers even after successfully deriving valid intermediate steps. Through systematic analysis, we observe that these failures frequently stem not from a lack of reasoning capacity, but from a deficiency in self-regulatory control, where valid logic is destabilized by uncontrolled exploration or the failure to recognize logical sufficiency. Motivated by this observation, we propose Metacognitive Behavioral Tuning (MBT), a post-training framework that explicitly injects metacognitive behaviors into the model's thought process. MBT implements this via two complementary formulations: (1) MBT-S, which synthesizes rigorous reasoning traces from scratch, and (2) MBT-R, which rewrites the student's initial traces to stabilize intrinsic exploration patterns. Experiments across multi-hop QA benchmarks demonstrate that MBT consistently outperforms baselines, achieving notable gains on challenging benchmarks. By effectively eliminating reasoning collapse, MBT achieves higher accuracy with significantly reduced token consumption, demonstrating that internalizing metacognitive strategies leads to more stable and robust reasoning.
Generating Dispatching Rules for the Interrupting Swap-Allowed Blocking Job Shop Problem Using Graph Neural Network and Reinforcement Learning
Feb 05, 2023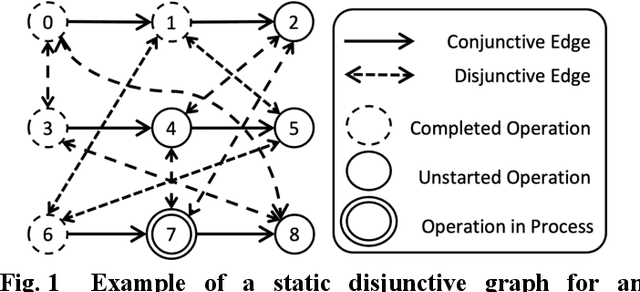
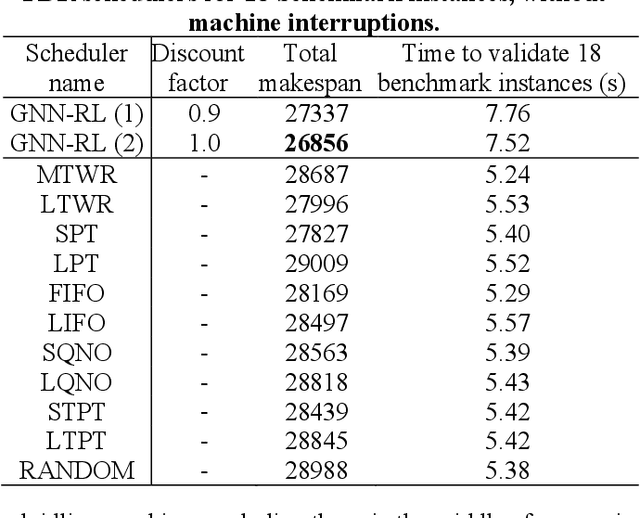
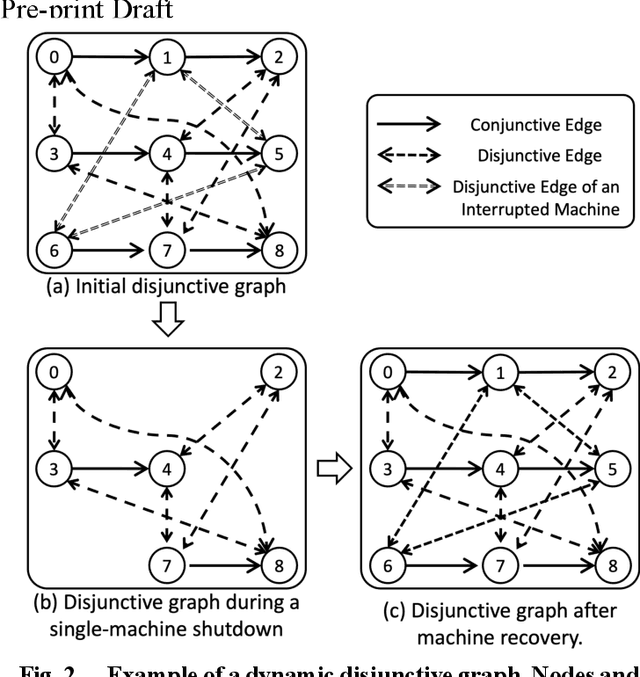
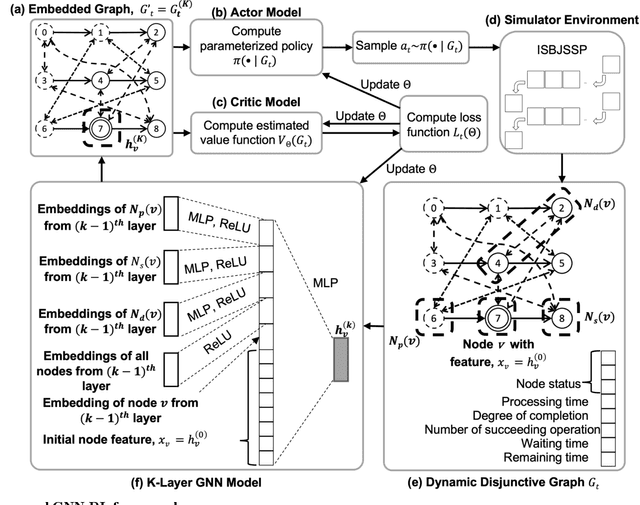
The interrupting swap-allowed blocking job shop problem (ISBJSSP) is a complex scheduling problem that is able to model many manufacturing planning and logistics applications realistically by addressing both the lack of storage capacity and unforeseen production interruptions. Subjected to random disruptions due to machine malfunction or maintenance, industry production settings often choose to adopt dispatching rules to enable adaptive, real-time re-scheduling, rather than traditional methods that require costly re-computation on the new configuration every time the problem condition changes dynamically. To generate dispatching rules for the ISBJSSP problem, a method that uses graph neural networks and reinforcement learning is proposed. ISBJSSP is formulated as a Markov decision process. Using proximal policy optimization, an optimal scheduling policy is learnt from randomly generated instances. Employing a set of reported benchmark instances, we conduct a detailed experimental study on ISBJSSP instances with a range of machine shutdown probabilities to show that the scheduling policies generated can outperform or are at least as competitive as existing dispatching rules with predetermined priority. This study shows that the ISBJSSP, which requires real-time adaptive solutions, can be scheduled efficiently with the proposed machine learning method when production interruptions occur with random machine shutdowns.
Learning to schedule job-shop problems: Representation and policy learning using graph neural network and reinforcement learning
Jun 02, 2021We propose a framework to learn to schedule a job-shop problem (JSSP) using a graph neural network (GNN) and reinforcement learning (RL). We formulate the scheduling process of JSSP as a sequential decision-making problem with graph representation of the state to consider the structure of JSSP. In solving the formulated problem, the proposed framework employs a GNN to learn that node features that embed the spatial structure of the JSSP represented as a graph (representation learning) and derive the optimum scheduling policy that maps the embedded node features to the best scheduling action (policy learning). We employ Proximal Policy Optimization (PPO) based RL strategy to train these two modules in an end-to-end fashion. We empirically demonstrate that the GNN scheduler, due to its superb generalization capability, outperforms practically favored dispatching rules and RL-based schedulers on various benchmark JSSP. We also confirmed that the proposed framework learns a transferable scheduling policy that can be employed to schedule a completely new JSSP (in terms of size and parameters) without further training.
* 16 pages, 8 figures