 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArBanking77: Intent Detection Neural Model and a New Dataset in Modern and Dialectical Arabic
Oct 29, 2023This paper presents the ArBanking77, a large Arabic dataset for intent detection in the banking domain. Our dataset was arabized and localized from the original English Banking77 dataset, which consists of 13,083 queries to ArBanking77 dataset with 31,404 queries in both Modern Standard Arabic (MSA) and Palestinian dialect, with each query classified into one of the 77 classes (intents). Furthermore, we present a neural model, based on AraBERT, fine-tuned on ArBanking77, which achieved an F1-score of 0.9209 and 0.8995 on MSA and Palestinian dialect, respectively. We performed extensive experimentation in which we simulated low-resource settings, where the model is trained on a subset of the data and augmented with noisy queries to simulate colloquial terms, mistakes and misspellings found in real NLP systems, especially live chat queries. The data and the models are publicly available at https://sina.birzeit.edu/arbanking77.
A Benchmark and Scoring Algorithm for Enriching Arabic Synonyms
Feb 04, 2023This paper addresses the task of extending a given synset with additional synonyms taking into account synonymy strength as a fuzzy value. Given a mono/multilingual synset and a threshold (a fuzzy value [0-1]), our goal is to extract new synonyms above this threshold from existing lexicons. We present twofold contributions: an algorithm and a benchmark dataset. The dataset consists of 3K candidate synonyms for 500 synsets. Each candidate synonym is annotated with a fuzzy value by four linguists. The dataset is important for (i) understanding how much linguists (dis/)agree on synonymy, in addition to (ii) using the dataset as a baseline to evaluate our algorithm. Our proposed algorithm extracts synonyms from existing lexicons and computes a fuzzy value for each candidate. Our evaluations show that the algorithm behaves like a linguist and its fuzzy values are close to those proposed by linguists (using RMSE and MAE). The dataset and a demo page are publicly available at https://portal.sina.birzeit.edu/synonyms.
Wojood: Nested Arabic Named Entity Corpus and Recognition using BERT
May 23, 2022
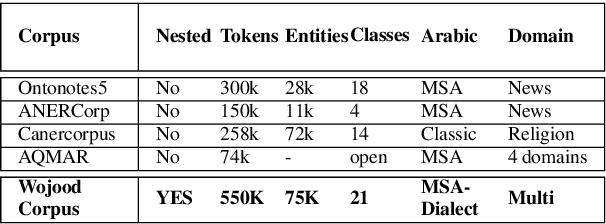

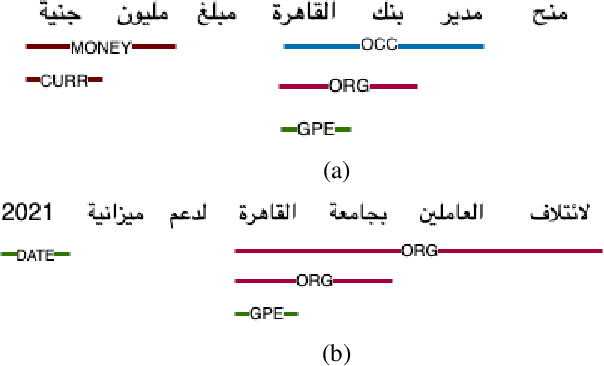
This paper presents Wojood, a corpus for Arabic nested Named Entity Recognition (NER). Nested entities occur when one entity mention is embedded inside another entity mention. Wojood consists of about 550K Modern Standard Arabic (MSA) and dialect tokens that are manually annotated with 21 entity types including person, organization, location, event and date. More importantly, the corpus is annotated with nested entities instead of the more common flat annotations. The data contains about 75K entities and 22.5% of which are nested. The inter-annotator evaluation of the corpus demonstrated a strong agreement with Cohen's Kappa of 0.979 and an F1-score of 0.976. To validate our data, we used the corpus to train a nested NER model based on multi-task learning and AraBERT (Arabic BERT). The model achieved an overall micro F1-score of 0.884. Our corpus, the annotation guidelines, the source code and the pre-trained model are publicly available.