 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEm-K Indexing for Approximate Query Matching in Large-scale ER
Nov 07, 2021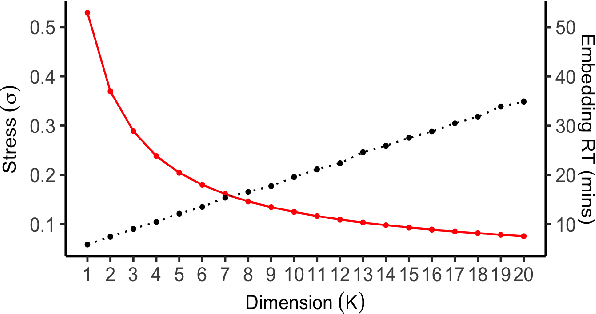
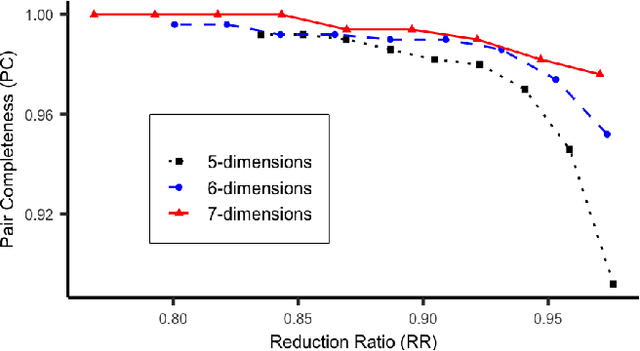
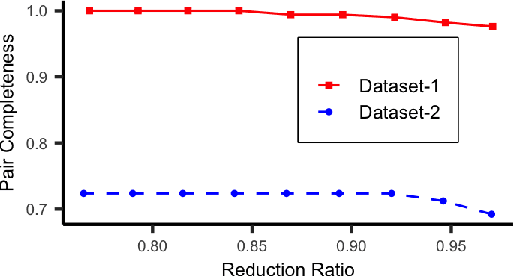
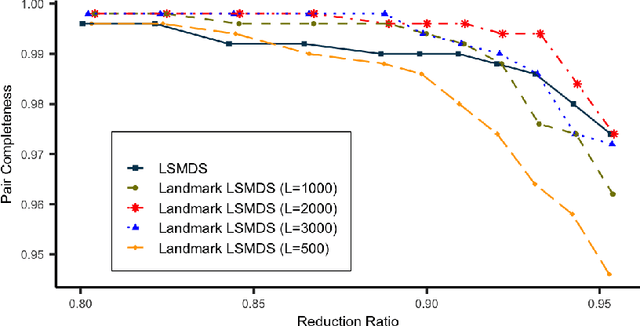
Accurate and efficient entity resolution (ER) is a significant challenge in many data mining and analysis projects requiring integrating and processing massive data collections. It is becoming increasingly important in real-world applications to develop ER solutions that produce prompt responses for entity queries on large-scale databases. Some of these applications demand entity query matching against large-scale reference databases within a short time. We define this as the query matching problem in ER in this work. Indexing or blocking techniques reduce the search space and execution time in the ER process. However, approximate indexing techniques that scale to very large-scale datasets remain open to research. In this paper, we investigate the query matching problem in ER to propose an indexing method suitable for approximate and efficient query matching. We first use spatial mappings to embed records in a multidimensional Euclidean space that preserves the domain-specific similarity. Among the various mapping techniques, we choose multidimensional scaling. Then using a Kd-tree and the nearest neighbour search, the method returns a block of records that includes potential matches for a query. Our method can process queries against a large-scale dataset using only a fraction of the data $L$ (given the dataset size is $N$), with a $O(L^2)$ complexity where $L \ll N$. The experiments conducted on several datasets showed the effectiveness of the proposed method.
High Performance Out-of-sample Embedding Techniques for Multidimensional Scaling
Nov 07, 2021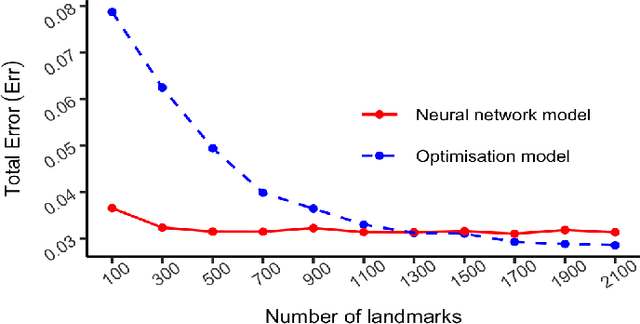
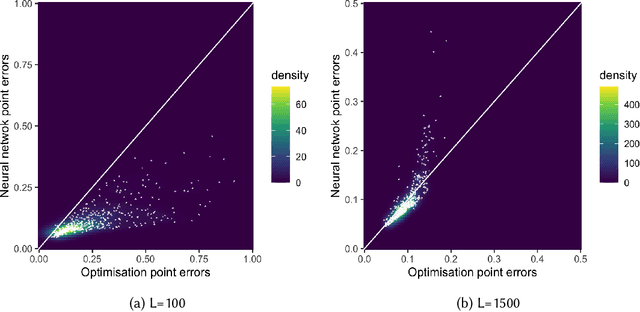
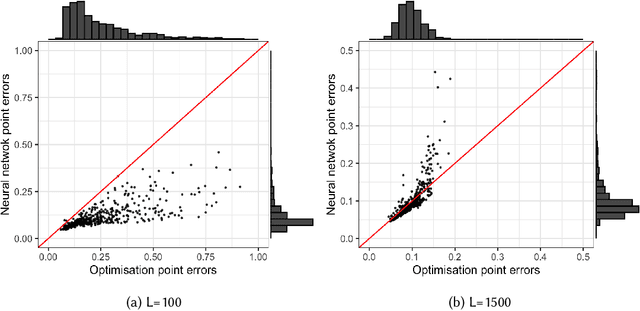
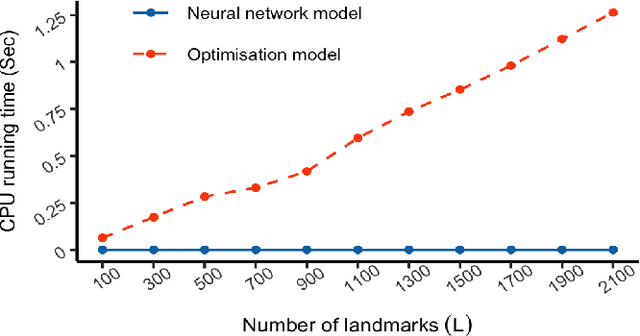
The recent rapid growth of the dimension of many datasets means that many approaches to dimension reduction (DR) have gained significant attention. High-performance DR algorithms are required to make data analysis feasible for big and fast data sets. However, many traditional DR techniques are challenged by truly large data sets. In particular multidimensional scaling (MDS) does not scale well. MDS is a popular group of DR techniques because it can perform DR on data where the only input is a dissimilarity function. However, common approaches are at least quadratic in memory and computation and, hence, prohibitive for large-scale data. We propose an out-of-sample embedding (OSE) solution to extend the MDS algorithm for large-scale data utilising the embedding of only a subset of the given data. We present two OSE techniques: the first based on an optimisation approach and the second based on a neural network model. With a minor trade-off in the approximation, the out-of-sample techniques can process large-scale data with reasonable computation and memory requirements. While both methods perform well, the neural network model outperforms the optimisation approach of the OSE solution in terms of efficiency. OSE has the dual benefit that it allows fast DR on streaming datasets as well as static databases.