 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Random Label Memorization for Unsupervised Pre-Training
Nov 05, 2018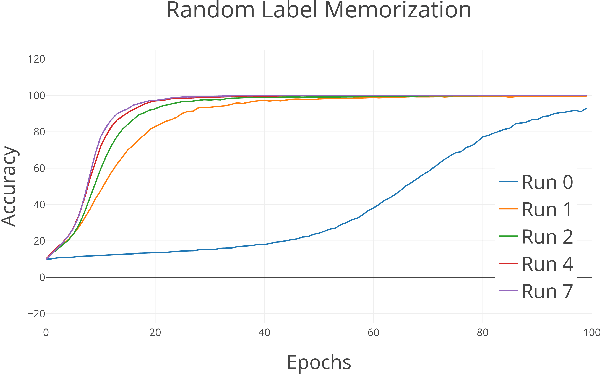

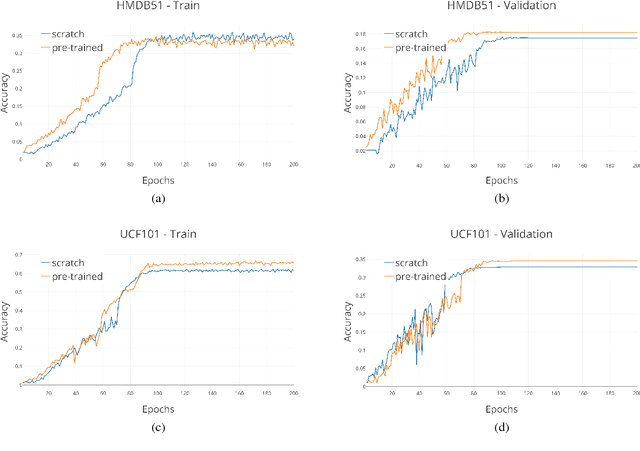

We present a novel approach to leverage large unlabeled datasets by pre-training state-of-the-art deep neural networks on randomly-labeled datasets. Specifically, we train the neural networks to memorize arbitrary labels for all the samples in a dataset and use these pre-trained networks as a starting point for regular supervised learning. Our assumption is that the "memorization infrastructure" learned by the network during the random-label training proves to be beneficial for the conventional supervised learning as well. We test the effectiveness of our pre-training on several video action recognition datasets (HMDB51, UCF101, Kinetics) by comparing the results of the same network with and without the random label pre-training. Our approach yields an improvement - ranging from 1.5% on UCF-101 to 5% on Kinetics - in classification accuracy, which calls for further research in this direction.