 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsiderations for the Interpretation of Bias Measures of Word Embeddings
Jun 19, 2019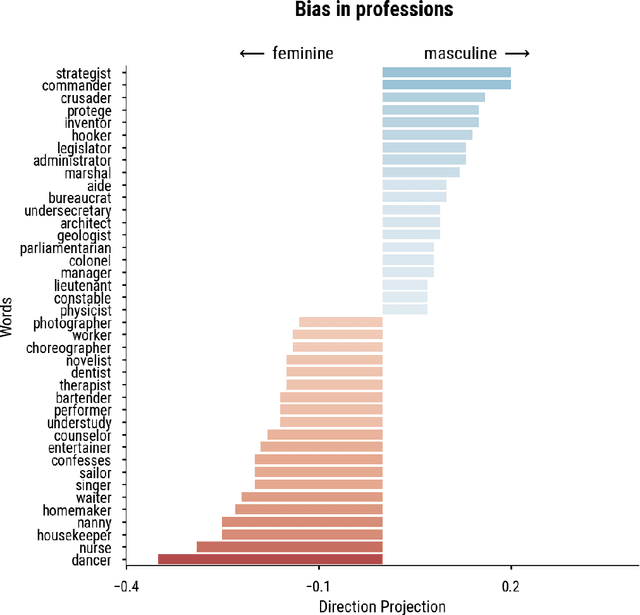
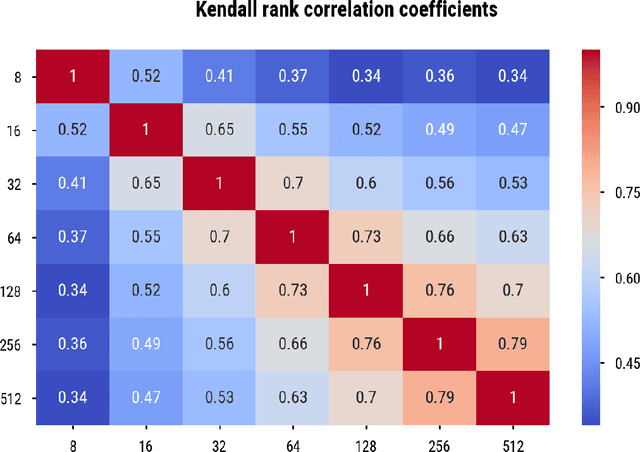
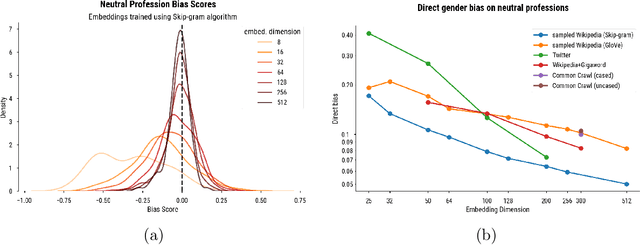
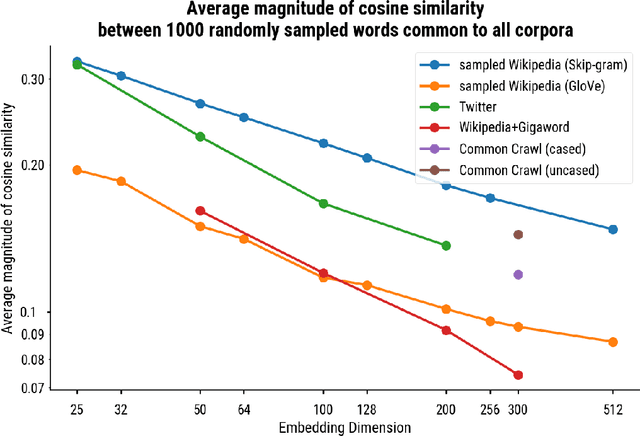
Word embedding spaces are powerful tools for capturing latent semantic relationships between terms in corpora, and have become widely popular for building state-of-the-art natural language processing algorithms. However, studies have shown that societal biases present in text corpora may be incorporated into the word embedding spaces learned from them. Thus, there is an ethical concern that human-like biases contained in the corpora and their derived embedding spaces might be propagated, or even amplified with the usage of the biased embedding spaces in downstream applications. In an attempt to quantify these biases so that they may be better understood and studied, several bias metrics have been proposed. We explore the statistical properties of these proposed measures in the context of their cited applications as well as their supposed utilities. We find that there are caveats to the simple interpretation of these metrics as proposed. We find that the bias metric proposed by Bolukbasi et al. 2016 is highly sensitive to embedding hyper-parameter selection, and that in many cases, the variance due to the selection of some hyper-parameters is greater than the variance in the metric due to corpus selection, while in fewer cases the bias rankings of corpora vary with hyper-parameter selection. In light of these observations, it may be the case that bias estimates should not be thought to directly measure the properties of the underlying corpus, but rather the properties of the specific embedding spaces in question, particularly in the context of hyper-parameter selections used to generate them. Hence, bias metrics of spaces generated with differing hyper-parameters should be compared only with explicit consideration of the embedding-learning algorithms particular configurations.
Pangloss: Fast Entity Linking in Noisy Text Environments
Jul 16, 2018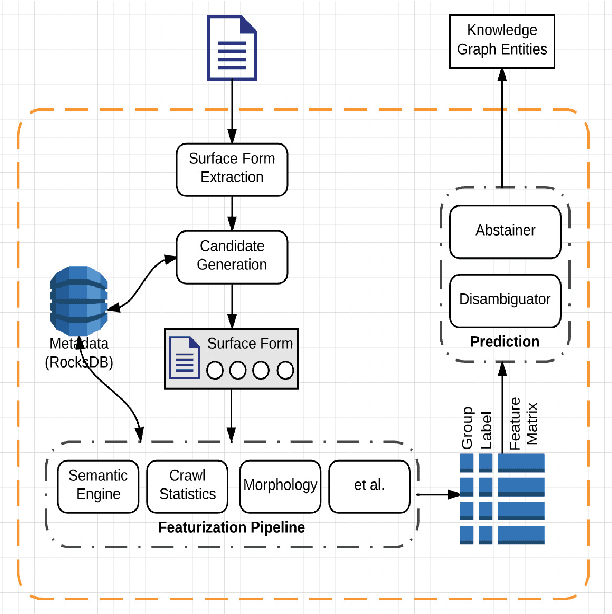
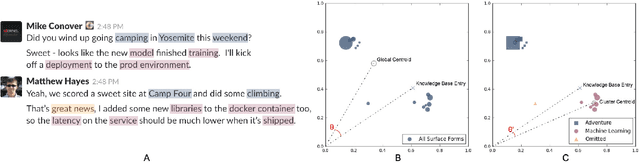
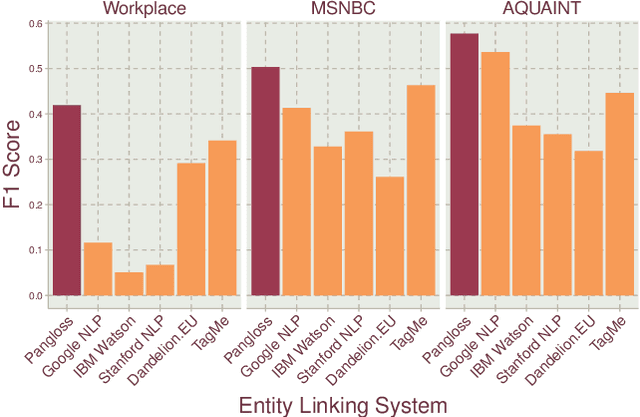
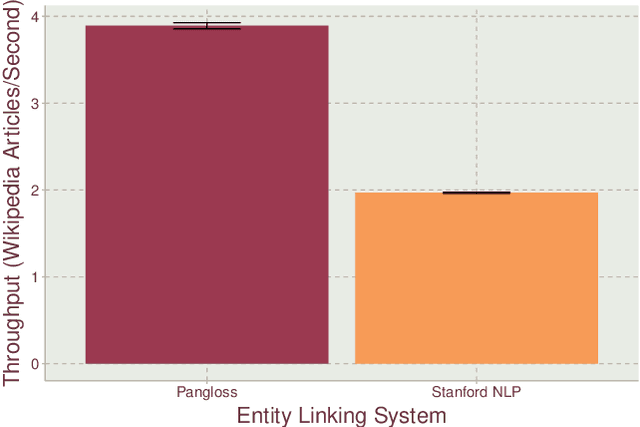
Entity linking is the task of mapping potentially ambiguous terms in text to their constituent entities in a knowledge base like Wikipedia. This is useful for organizing content, extracting structured data from textual documents, and in machine learning relevance applications like semantic search, knowledge graph construction, and question answering. Traditionally, this work has focused on text that has been well-formed, like news articles, but in common real world datasets such as messaging, resumes, or short-form social media, non-grammatical, loosely-structured text adds a new dimension to this problem. This paper presents Pangloss, a production system for entity disambiguation on noisy text. Pangloss combines a probabilistic linear-time key phrase identification algorithm with a semantic similarity engine based on context-dependent document embeddings to achieve better than state-of-the-art results (>5% in F1) compared to other research or commercially available systems. In addition, Pangloss leverages a local embedded database with a tiered architecture to house its statistics and metadata, which allows rapid disambiguation in streaming contexts and on-device disambiguation in low-memory environments such as mobile phones.