Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUBES: A Corpus of Negation and Uncertainty in Spanish Clinical Texts
Apr 02, 2020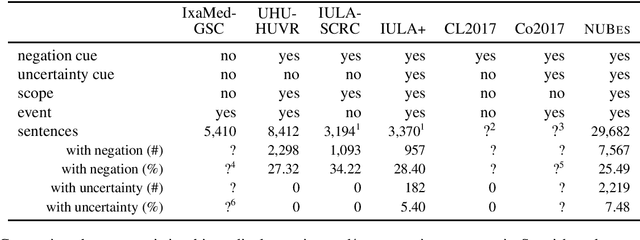
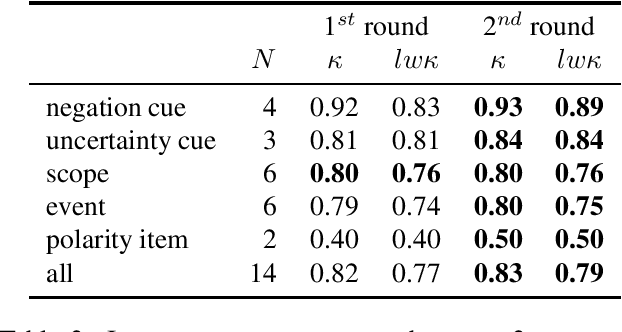
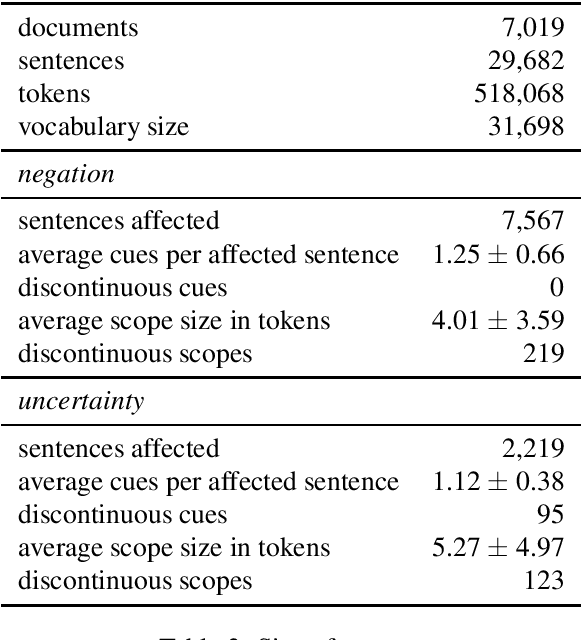
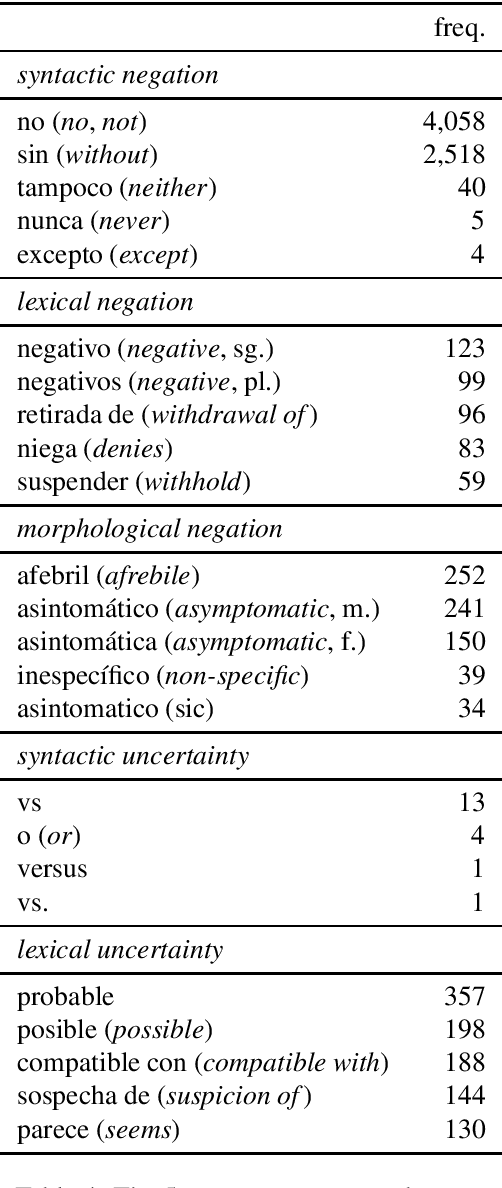
This paper introduces the first version of the NUBes corpus (Negation and Uncertainty annotations in Biomedical texts in Spanish). The corpus is part of an on-going research and currently consists of 29,682 sentences obtained from anonymised health records annotated with negation and uncertainty. The article includes an exhaustive comparison with similar corpora in Spanish, and presents the main annotation and design decisions. Additionally, we perform preliminary experiments using deep learning algorithms to validate the annotated dataset. As far as we know, NUBes is the largest publicly available corpus for negation in Spanish and the first that also incorporates the annotation of speculation cues, scopes, and events.
* Accepted at the Twelfth International Conference on Language
Resources and Evaluation (LREC 2020)
Via