 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Mapping Study on Testing of Machine Learning Programs
Jul 11, 2019
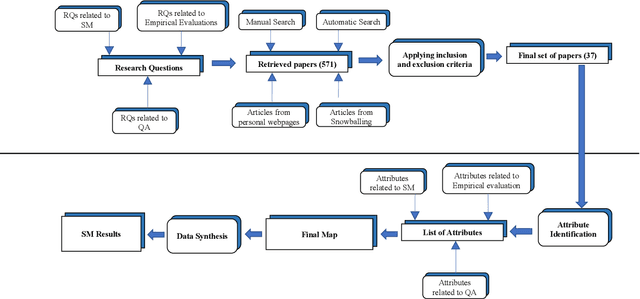

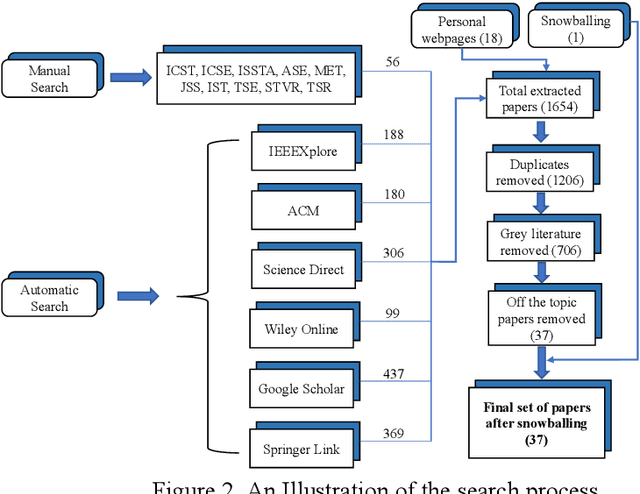
We aim to conduct a systematic mapping in the area of testing ML programs. We identify, analyze and classify the existing literature to provide an overview of the area. We followed well-established guidelines of systematic mapping to develop a systematic protocol to identify and review the existing literature. We formulate three sets of research questions, define inclusion and exclusion criteria and systematically identify themes for the classification of existing techniques. We also report the quality of the published works using established assessment criteria. we finally selected 37 papers out of 1654 based on our selection criteria up to January 2019. We analyze trends such as contribution facet, research facet, test approach, type of ML and the kind of testing with several other attributes. We also discuss the empirical evidence and reporting quality of selected papers. The data from the study is made publicly available for other researchers and practitioners. We present an overview of the area by answering several research questions. The area is growing rapidly, however, there is lack of enough empirical evidence to compare and assess the effectiveness of the techniques. More publicly available tools are required for use of practitioners and researchers. Further attention is needed on non-functional testing and testing of ML programs using reinforcement learning. We believe that this study can help researchers and practitioners to obtain an overview of the area and identify several sub-areas where more research is required