 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated System-level Testing of Unmanned Aerial Systems
Mar 23, 2024Unmanned aerial systems (UAS) rely on various avionics systems that are safety-critical and mission-critical. A major requirement of international safety standards is to perform rigorous system-level testing of avionics software systems. The current industrial practice is to manually create test scenarios, manually/automatically execute these scenarios using simulators, and manually evaluate outcomes. The test scenarios typically consist of setting certain flight or environment conditions and testing the system under test in these settings. The state-of-the-art approaches for this purpose also require manual test scenario development and evaluation. In this paper, we propose a novel approach to automate the system-level testing of the UAS. The proposed approach (AITester) utilizes model-based testing and artificial intelligence (AI) techniques to automatically generate, execute, and evaluate various test scenarios. The test scenarios are generated on the fly, i.e., during test execution based on the environmental context at runtime. The approach is supported by a toolset. We empirically evaluate the proposed approach on two core components of UAS, an autopilot system of an unmanned aerial vehicle (UAV) and cockpit display systems (CDS) of the ground control station (GCS). The results show that the AITester effectively generates test scenarios causing deviations from the expected behavior of the UAV autopilot and reveals potential flaws in the GCS-CDS.
Efficient Test Data Generation for MC/DC with OCL and Search
Jan 07, 2024



System-level testing of avionics software systems requires compliance with different international safety standards such as DO-178C. An important consideration of the avionics industry is automated test data generation according to the criteria suggested by safety standards. One of the recommended criteria by DO-178C is the modified condition/decision coverage (MC/DC) criterion. The current model-based test data generation approaches use constraints written in Object Constraint Language (OCL), and apply search techniques to generate test data. These approaches either do not support MC/DC criterion or suffer from performance issues while generating test data for large-scale avionics systems. In this paper, we propose an effective way to automate MC/DC test data generation during model-based testing. We develop a strategy that utilizes case-based reasoning (CBR) and range reduction heuristics designed to solve MC/DC-tailored OCL constraints. We performed an empirical study to compare our proposed strategy for MC/DC test data generation using CBR, range reduction, both CBR and range reduction, with an original search algorithm, and random search. We also empirically compared our strategy with existing constraint-solving approaches. The results show that both CBR and range reduction for MC/DC test data generation outperform the baseline approach. Moreover, the combination of both CBR and range reduction for MC/DC test data generation is an effective approach compared to existing constraint solvers.
A Systematic Mapping Study on Testing of Machine Learning Programs
Jul 11, 2019
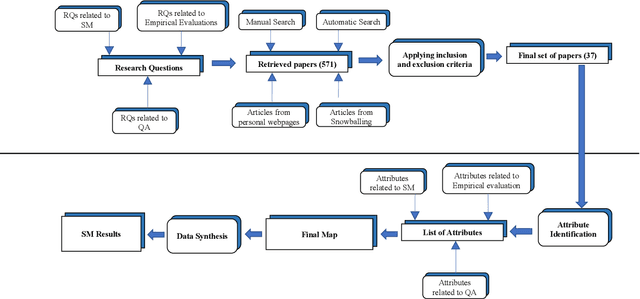

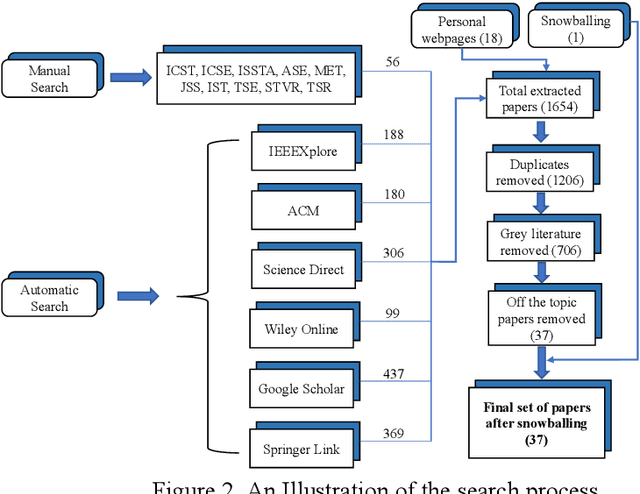
We aim to conduct a systematic mapping in the area of testing ML programs. We identify, analyze and classify the existing literature to provide an overview of the area. We followed well-established guidelines of systematic mapping to develop a systematic protocol to identify and review the existing literature. We formulate three sets of research questions, define inclusion and exclusion criteria and systematically identify themes for the classification of existing techniques. We also report the quality of the published works using established assessment criteria. we finally selected 37 papers out of 1654 based on our selection criteria up to January 2019. We analyze trends such as contribution facet, research facet, test approach, type of ML and the kind of testing with several other attributes. We also discuss the empirical evidence and reporting quality of selected papers. The data from the study is made publicly available for other researchers and practitioners. We present an overview of the area by answering several research questions. The area is growing rapidly, however, there is lack of enough empirical evidence to compare and assess the effectiveness of the techniques. More publicly available tools are required for use of practitioners and researchers. Further attention is needed on non-functional testing and testing of ML programs using reinforcement learning. We believe that this study can help researchers and practitioners to obtain an overview of the area and identify several sub-areas where more research is required